本文主要从原理、计算流程、应用场景等方面介绍了5个客户模型,enjoy~

不久前,淘宝推出了”88VIP卡”,可享受购物折扣、饿了么超级会员、优酷VIP、虾米超级VIP等尊享服务,权益价值近2000元/年,几乎涵盖阿里新零售生态旗下吃喝玩乐的一条龙服务。这样的一张会员卡,普通会员售价888元/年,而淘气值满1000的超级会员,仅售88元/年,真的是不要998。
虽然笔者并没有资格享受,但是对淘气值很好奇。官方是这样解释的:
淘气值是根据会员近12个月在淘宝、天猫,飞猪以及淘票票上的”购买金额、购买频次、互动、信誉“等行为,而综合计算出的会员价值分。
简单解读,淘气值就是阿里对客户价值的度量,背后是一套成熟的计算模型。淘气值是阿里的会员养成体系,大于1000的客户,阿里认为是高价值客户,可以提供差异化的产品和服务,增大使用粘性,并为旗下其他产品引流;小于1000的客户,则引导其向高价值客户转化(虽然包括小编在内的好多用户,都感觉受到了1w点伤害)。
由此可见,企业在对客户全生命周期管理的过程中,往往会针对不同阶段的客户群体进行细分,提供差异化的产品和服务,从而达到精细化运营的目的。实际工程中,客户群体的细分一般依据客户的:标签、线上行为、线下行为等作为判断条件。其中,有一类标签是通过大数据建模才能产出。
本文主要从原理、计算流程、应用场景等方面,介绍了5个客户模型:
3个客户评估模型:RFM模型、忠诚度模型、活跃度模型; 1个客户细分模型:Look-alike模型; 1个客户响应模型:流失预警模型。 一. 建模流程建模的过程一般分为以下几个步骤:
业务理解:明确面临的标签问题和建模的目的,完成标签问题到建模问题的定义过程; 数据理解:收集涉及到的数据、熟悉数据、识别数据质量问题、探索对数据的第一认识; 数据准备:从原始未加工数据到构造成最终的数据集过程; 建立模型:针对不同的标签问题选择建模技术,并对参数进行调优; 模型评估:评估模型和检查建模的各个步骤,确认是否达到解决标签问题; 模型部署:将模型部署到系统中,并对监控、维护该模型做出计划。 1. RMF模型RFM模型是客户价值分析模型。该模型通过分析客户的近期消费行为、消费频率及消费金额,来衡量客户价值及创造利润能力,为客户价值分析、流失预警分析等精细化运营提供依据。
R:Regency(近度),即客户最近一次交易与当前时间的间隔。 F:Requency(频度),即客户的交易频率。 M:Montary(额度),即客户的交易金额。该模型的输入数据为:最近一次交易时间、交易频率、交易金额这三个核心指标,分别计算出每个指标数据的均值,分别以avg(R)、avg(F)、avg(M)表示,然后将每位客户的三个指标值分别与平均值进行对比,K-means聚类分析,可得出以下8类客户价值群体:
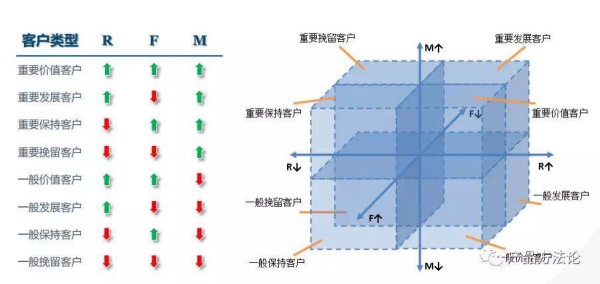
输入的数据集经过RFM模型分析后,给每条数据里的客户打上八种标签值的其中一个,企业通过标签值筛选出不同的客户群后,就可以执行相应的贡献度分析、预警流失客户挽回等精细化运营,如:
给重要价值客户定时提供差异化尊享服务(淘气值1000以上提供88VIP会员卡);
给重要保持客户建立EDM或电话营销等互动通道,及时唤醒并提高活跃度(近3个月没有信用交易的客户,电话推销告知提升客户额度并可提现);
重要挽留客户是优质的存量用户群,要给予限时折扣或权益,投入精力重点挽回。
注:聚类是一种非监督式学习算法,聚类不要求源数据集有标注,一般应用于做数据探索性分析,聚类算法的结果是将不同的数据集按照各自的典型特征分成不同类别。
而k-means聚类算法的思想是:初始随机给定K个簇中心,按照距离最近原则把待分类的样本点分到各个簇,然后按平均法重新计算各个簇的质心,从而确定新的簇心,迭代计算,直到簇心的移动距离小于某个给定的误差值。
2. 忠诚度模型客户忠诚度是客户对某种产品或服务重复或连续购买的心理、言语、行为指向程度的度量。对企业而言,忠诚顾客能够产品持续的、长期的效益。传统的CRM有个“八一定律”,即拉动1个新用户,是用维系老用户的8倍成本来实现的。随着人口红利的消失,现如今企业越来越重视存量市场,所以刻画客户对产品或品牌的忠诚度尤为重要。
品牌忠诚度依据:
网站忠诚度的5个指标,即用户累计浏览品牌的次数、累计浏览时间、累计浏览天数、累计浏览页面数、最后浏览时间; 品牌忠诚的9个指标,即累计购买某品牌商品的次数、累计购买某品牌商品的金额、最后一次购买某品牌的时间、累计搜索某品牌关键字的次数、用户浏览同类其他品牌的累计平均次数、用户浏览同类其他品牌的累计平均浏览时间、用户浏览同类其他品牌的累计平均浏览天数、用户浏览同类其他品牌的累计平均浏览页面数、用户浏览同类其他品牌的最后平均浏览时间。结合具体业务场景下给定的各项指标的权重值,来计算用户的忠诚度。所有权重值之和为1,最后将忠诚度的值映射到1到100之间。依据忠诚度落在不同区间的值,将中文用户等级结果写到标签系统。
依据标签筛选的客户群体细分为几类群体,分群组进行精细化运营,例如:潜在忠诚客户群体提高搜索权重,加大品牌认知;高忠诚客户群体复购时推荐高价值商品;建立积分商城,长期培养监测客户忠诚度的养成等。
3. 活跃度模型
一般的,企业可通过活跃用户数,看产品的市场体量,通过活跃率,看产品的健康度。日常的促活运营活动,需要通过活跃度标签筛选人群。
首先,根据业务规则选定输入因子,如电商行业的输入行为特征一般为:最后一次登录时间、最后一次购买时间、半年内评论数、半年内购买数、累计登录天数、累计停留时间、浏览页面数等,然后计算活跃度得分。
分析活跃度得分,输出结果标签逻辑如下:
高活跃度客户(活跃度得分前30%),表示客户粘性高,是企业的核心用户。 中活跃度客户(中间部分),表示客户与企业产品交互程度一般,需要继续维持。 低活跃度客户(活跃度得分后30%),即沉睡客户,是企业日常促活运营的重点对象。 4. Look-alike模型Look-alike模型,即受众扩散模型,模型原理是以种子客群为基础,找到与种子客群兴趣爱好相似的另一组人群,计算两组人群的相似度或以群组距离进行分类,从而达到精准挖掘潜在受众、扩大推广范围的目的。人群扩散在推销新商品、寻找潜客、开发客户购买力等多种场景下都起着关键作用。
受众扩散模型的基本流程如下:
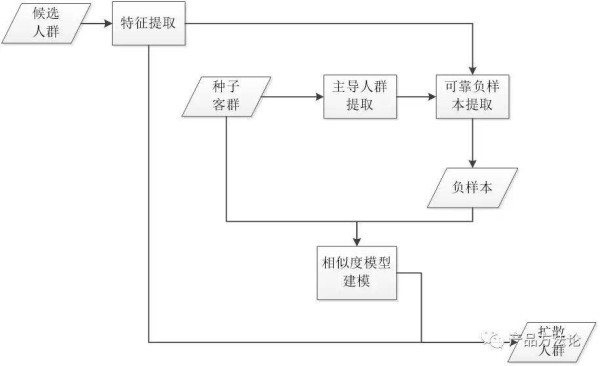
常见的二分类算法有LR逻辑回归,决策树,SVM,随机森林等。
特征的选取一般包含用户的:
属性标签数据。如性别、年龄、地域、婚姻状况、受教育水平、职业等,一般来自用户注册信息或预测; 行为结果数据。如电商用户的站内外搜索、浏览、购买等行为,媒体用户的关注、转发等行为,一般为用户实际发生行为的日志; 行为偏好数据。如电商用户的消费等级、商品品类偏好、商品品牌偏好,媒体用户的上网时段、浏览频道偏好等,一般根据用户行为计算分析而得出; 社交网络数据。利用用户的社交关系网络,将种子人群的标签或属性扩散给好友。如微博的粉丝关注、转发行为等构成的社交关系网络。 5. 流失预警模型流失预警模型,即根据客户的多维特征,判断系统内的客户有多大概率流失,根据流失概率分群,针对潜在流失客户群体制定针对性的挽回营销策略。
流程预警模型的大致流程如下:
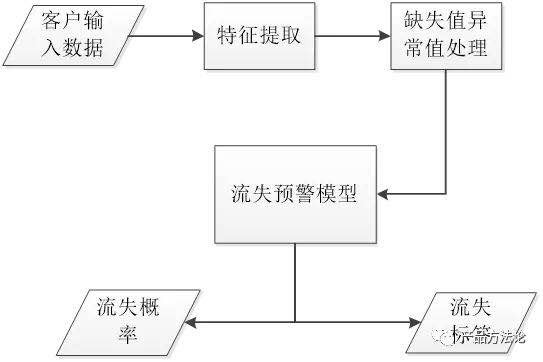
一般的,根据流失概率分布,可输出为以下四个标签值:
正常(流失概率0~0.2),表示流失的概率基本很小,可忽略不计; 轻度(流失概率0.2~0.5),表示有潜在流失风险,需要重点关注; 严重(流失概率0.5~0.8),表示有明显的流失倾向,需要重点维系,必要时可以有主动触达; 非常严重(0.8~1.0),表示有非常严重的流失倾向,需要主动与客户以EDM或电话等形式发生互动,及时挽回。— END —
作者:Herman Lee ,公众号:产品方法论(ID:HermanLee2018)
本文由 @Herman Lee 原创发布于人人都是产品经理。未经许可,禁止转载。返回搜狐,查看更多
责任编辑: