Hadoop实战:微博数据分析
项目需求
自定义输入格式,将明星微博数据排序后按粉丝数 关注数 微博数 分别输出到不同文件中。
数据集
下面是部分数据,猛戳此链接下载完整数据集
数据格式: 明星 明星微博名称 粉丝数 关注数 微博数
黄晓明 黄晓明 22616497 506 2011
张靓颖 张靓颖 27878708 238 3846
羅志祥 羅志祥 30763518 277 3843
劉嘉玲 劉嘉玲 12631697 350 2057
李娜 李娜 23309493 81 631
成龙 成龙 22485765 5 758
...
思路分析
自定义的InputFormat读取明星微博数据,通过getSortedHashtableByValue分别对明星follower、friend、statuses数据进行排序,然后利用MultipleOutputs输出不同项到不同的文件中。
程序
Weibo.java
package com.hadoop.WeiboCount;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/*
数据格式: 明星 明星微博名称 粉丝数 关注数 微博数
黄晓明 黄晓明 22616497 506 2011
张靓颖 张靓颖 27878708 238 3846
张成龙2012 张成龙2012 9813621 199 744
羅志祥 羅志祥 30763518 277 3843
劉嘉玲 劉嘉玲 12631697 350 2057
吳君如大美女 吳君如大美女 18490338 190 412
柯震東Kai 柯震東Kai 31337479 219 795
李娜 李娜 23309493 81 631
徐小平 徐小平 11659926 1929 13795
唐嫣 唐嫣 24301532 200 2391
有斐君 有斐君 8779383 577 4251
孙燕姿 孙燕姿 21213839 68 342
成龙 成龙 22485765 5 758
*/
public class WeiBo implements WritableComparable<Object> {
// 其实这里,跟TVPlayData和ScoreWritable一样的
// 注意: Hadoop通过Writable接口实现的序列化机制,不过没有提供比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。(自定义比较)
// Writable接口提供两个方法(write和readFields)。
// 直接利用java的基本数据类型int,定义成员变量fan、followers、microblogs
// 粉丝
private int fan;
// 关注
private int followers;
// 微博数
private int microblogs;
// 问:这里我们自己编程时,是一定要创建一个带有参的构造方法,为什么还要显式的写出来一个带无参的构造方法呢?
// 答:构造器其实就是构造对象实例的方法,无参数的构造方法是默认的,但是如果你创造了一个带有参数的构造方法,那么无参的构造方法必须显式的写出来,否则会编译失败。
public WeiBo(){}; //java里的无参构造函数,是用来在创建对象时初始化对象
//在hadoop的每个自定义类型代码里,好比,现在的WeiBo,都必须要写无参构造函数。
//问:为什么我们在编程的时候,需要创建一个带有参的构造方法?
//答:就是能让赋值更灵活。构造一般就是初始化数值,你不想别人用你这个类的时候每次实例化都能用另一个构造动态初始化一些信息么(当然没有需要额外赋值就用默认的)。
public WeiBo(int fan,int followers,int microblogs){
this.fan = fan;
this.followers = followers;
this.microblogs = microblogs;
}
//问:其实set和get方法,这两个方法只是类中的setxxx和getxxx方法的总称,
//那么,为什么在编程时,有set和set***两个,只有get***一个呢?
public void set(int fan,int followers,int microblogs){
this.fan = fan;
this.followers = followers;
this.microblogs = microblogs;
}
// public float get(int fan,int followers,int microblogs){因为这是错误的,所以对于set可以分开,get只能是get***
// return fan;
// return followers;
// return microblogs;
//}
// 实现WritableComparable的readFields()方法,以便该数据能被序列化后完成网络传输或文件输入
// 对象不能传输的,需要转化成字节流!
// 将对象转换为字节流并写入到输出流out中是序列化,write 的过程(最好记!!!)
// 从输入流in中读取字节流反序列化为对象 是反序列化,readFields的过程(最好记!!!)
@Override
public void readFields(DataInput in) throws IOException {
//拿代码来说的话,对象就是比如fan、followers。。。。
fan = in.readInt(); //因为,我们这里的对象是Int类型,所以是readInt()
followers = in.readInt();
microblogs = in.readInt(); //注意:反序列化里,需要生成对象对吧,所以,是用到的是get对象
// in.readByte()
// in.readChar()
// in.readDouble()
// in.readLine()
// in.readFloat()
// in.readLong()
// in.readShort()
}
// 实现WritableComparable的write()方法,以便该数据能被序列化后完成网络传输或文件输出
// 将对象转换为字节流并写入到输出流out中是序列化,write 的过程(最好记!!!)
// 从输入流in中读取字节流反序列化为对象 是反序列化,readFields的过程(最好记!!!)
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(fan);
out.writeInt(followers); //因为,我们这里的对象是Int类型,所以是writeInt()
out.writeInt(microblogs); //注意:序列化里,需要对象对吧,所以,用到的是set那边的对象
// out.writeByte()
// out.writeChar()
// out.writeDouble()
// out.writeFloat()
// out.writeLong()
// out.writeShort()
// out.writeUTF()
}
@Override
public int compareTo(Object o) { //java里的比较,Java String.compareTo()
// TODO Auto-generated method stub
return 0;
}
// Hadoop中定义了两个序列化相关的接口:Writable 接口和 Comparable 接口,这两个接口可以合并成一个接口 WritableComparable。
// Writable 接口中定义了两个方法,分别为write(DataOutput out)和readFields(DataInput in)
// 所有实现了Comparable接口的对象都可以和自身相同类型的对象比较大小
// 源码是
// package java.lang;
// import java.util.*;
// public interface Comparable {
// /**
// * 将this对象和对象o进行比较,约定:返回负数为小于,零为大于,整数为大于
// */
// public int compareTo(T o);
// }
public int getFan() {
return fan;
}
public void setFan(int fan) {
this.fan = fan;
}
public int getFollowers() {
return followers;
}
public void setFollowers(int followers) {
this.followers = followers;
}
public int getMicroblogs() {
return microblogs;
}
public void setMicroblogs(int microblogs) {
this.microblogs = microblogs;
}
}
WeiboCount.java
package com.hadoop.WeiboCount;
import java.io.IOException;
import java.util.Arrays;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.LazyOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WeiboCount extends Configured implements Tool {
// tab分隔符
private static String TAB_SEPARATOR = "\t";
// 粉丝
private static String FAN = "fan";
// 关注
private static String FOLLOWERS = "followers";
// 微博数
private static String MICROBLOGS = "microblogs";
public static class WeiBoMapper extends Mapper<Text, WeiBo, Text, Text> {
@Override
protected void map(Text key, WeiBo value, Context context) throws IOException, InterruptedException {
// 粉丝
context.write(new Text(FAN), new Text(key.toString() + TAB_SEPARATOR + value.getFan()));
// 关注
context.write(new Text(FOLLOWERS), new Text(key.toString() + TAB_SEPARATOR + value.getFollowers()));
// 微博数
context.write(new Text(MICROBLOGS), new Text(key.toString() + TAB_SEPARATOR + value.getMicroblogs()));
}
}
public static class WeiBoReducer extends Reducer<Text, Text, Text, IntWritable> {
private MultipleOutputs<Text, IntWritable> mos;
protected void setup(Context context) throws IOException, InterruptedException {
mos = new MultipleOutputs<Text, IntWritable>(context);
}
protected void reduce(Text Key, Iterable<Text> Values,Context context) throws IOException, InterruptedException {
Map<String,Integer> map = new HashMap< String,Integer>();
for(Text value : Values){ //增强型for循环,意思是把Values的值传给Text value
// value = 名称 + (粉丝数 或 关注数 或 微博数)
String[] records = value.toString().split(TAB_SEPARATOR);
map.put(records[0], Integer.parseInt(records[1].toString()));
}
// 对Map内的数据进行排序
Map.Entry<String, Integer>[] entries = getSortedHashtableByValue(map);
for(int i = 0; i < entries.length;i++){
mos.write(Key.toString(),entries[i].getKey(), entries[i].getValue());
}
}
protected void cleanup(Context context) throws IOException, InterruptedException {
mos.close();
}
}
@SuppressWarnings("deprecation")
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration(); // 配置文件对象
// 判断路径是否存在,如果存在,则删除
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "weibo"); // 构造任务
job.setJarByClass(WeiboCount.class); // 主类
// Mapper
job.setMapperClass(WeiBoMapper.class);
// Mapper key输出类型
job.setMapOutputKeyClass(Text.class);
// Mapper value输出类型
job.setMapOutputValueClass(Text.class);
// Reducer
job.setReducerClass(WeiBoReducer.class);
// Reducer key输出类型
job.setOutputKeyClass(Text.class);
// Reducer value输出类型
job.setOutputValueClass(IntWritable.class);
// 输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 自定义输入格式
job.setInputFormatClass(WeiboInputFormat.class) ;
//自定义文件输出类别
MultipleOutputs.addNamedOutput(job, FAN, TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, FOLLOWERS, TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, MICROBLOGS, TextOutputFormat.class, Text.class, IntWritable.class);
// 去掉job设置outputFormatClass,改为通过LazyOutputFormat设置
LazyOutputFormat.setOutputFormatClass(job, TextOutputFormat.class);
//提交任务
return job.waitForCompletion(true)?0:1;
}
// 对Map内的数据进行排序(只适合小数据量)
@SuppressWarnings("unchecked")
public static Entry<String, Integer>[] getSortedHashtableByValue(Map<String, Integer> h) {
Entry<String, Integer>[] entries = (Entry<String, Integer>[]) h.entrySet().toArray(new Entry[0]);
// 排序
Arrays.sort(entries, new Comparator<Entry<String, Integer>>() {
public int compare(Entry<String, Integer> entry1, Entry<String, Integer> entry2) {
return entry2.getValue().compareTo(entry1.getValue());
}
});
return entries;
}
public static void main(String[] args) throws Exception {
String[] args0 = { "hdfs://centpy:9000/weibo/weibo.txt", "hdfs://centpy:9000/weibo/out/" };
// String[] args0 = { "./data/weibo/weibo.txt", "./out/weibo/" };
int ec = ToolRunner.run(new Configuration(), new WeiboCount(), args0);
System.exit(ec);
}
}
WeiboInputFormat.java
package com.hadoop.WeiboCount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
//其实这个程序,就是在实现InputFormat接口,TVPlayInputFormat是InputFormat接口的实现类
//比如 WeiboInputFormat extends FileInputFormat implements InputFormat。
//问:自定义输入格式 WeiboInputFormat 类,首先继承 FileInputFormat,然后分别重写 isSplitable() 方法和 createRecordReader() 方法。
//线路是: boolean isSplitable() -> RecordReader<Text,WeiBo> createRecordReader() -> WeiboRecordReader extends RecordReader<Text, WeiBo >
public class WeiboInputFormat extends FileInputFormat<Text,WeiBo>{
@Override
protected boolean isSplitable(JobContext context, Path filename) {//这是InputFormat的isSplitable方法
//isSplitable方法就是是否要切分文件,这个方法显示如果是压缩文件就不切分,非压缩文件就切分。
// 如果不允许分割,则isSplitable==false,则将第一个block、文件目录、开始位置为0,长度为整个文件的长度封装到一个InputSplit,加入splits中
// 如果文件长度不为0且支持分割,则isSplitable==true,获取block大小,默认是64MB
return false; //整个文件封装到一个InputSplit
//要么就是return true; //切分64MB大小的一块一块,再封装到InputSplit
}
@Override
public RecordReader<Text, WeiBo> createRecordReader(InputSplit arg0, TaskAttemptContext arg1) throws IOException, InterruptedException {
// RecordReader<k1, v1>是返回类型,返回的RecordReader对象的封装
// createRecordReader是方法,在这里是,WeiboInputFormat.createRecordReader。WeiboInputFormat是InputFormat类的实例
// InputSplit input和TaskAttemptContext context是传入参数
// isSplitable(),如果是压缩文件就不切分,整个文件封装到一个InputSplit
// isSplitable(),如果是非压缩文件就切,切分64MB大小的一块一块,再封装到InputSplit
//这里默认是系统实现的的RecordReader,按行读取,下面我们自定义这个类WeiboRecordReader。
//类似与Excel、WeiBo、TVPlayData代码写法
// 自定义WeiboRecordReader类,按行读取
return new WeiboRecordReader(); //新建一个ScoreRecordReader实例,所有才有了上面RecordReader<Text,ScoreWritable>,所以才如下ScoreRecordReader,写我们自己的
}
public class WeiboRecordReader extends RecordReader<Text, WeiBo>{
//LineReader in是1,行号。
//Text line; 俞灏明 俞灏明 10591367 206 558,每行的相关记录
public LineReader in; //行读取器
public Text line;//每行数据类型
public Text lineKey;//自定义key类型,即k1
public WeiBo lineValue;//自定义value类型,即v1
@Override
public void initialize(InputSplit input, TaskAttemptContext context) throws IOException, InterruptedException { //初始化,都是模板
FileSplit split = (FileSplit)input; // 获取split
Configuration job = context.getConfiguration(); // 获取配置
Path file = split.getPath(); // 分片路径
FileSystem fs = file.getFileSystem(job);
FSDataInputStream filein = fs.open(file); // 打开文件
in=new LineReader(filein,job); //输入流in
line=new Text();//每行数据类型
lineKey=new Text();//自定义key类型,即k1。//新建一个Text实例作为自定义格式输入的key
lineValue = new WeiBo();//自定义value类型,即v1。//新建一个TVPlayData实例作为自定义格式输入的value
}
//此方法读取每行数据,完成自定义的key和value
@Override
public boolean nextKeyValue() throws IOException, InterruptedException { //这里面,才是篡改的重点
// 一行数据
Text line = new Text();
int linesize = in.readLine(line); //line是每行数据,我们这里用到的是in.readLine(str)这个构造函数,默认读完读到文件末尾。其实这里有三种。
// 是SplitLineReader.readLine -> SplitLineReader extends LineReader -> org.apache.hadoop.util.LineReader
// in.readLine(str)//这个构造方法执行时,会首先将value原来的值清空。默认读完读到文件末尾
// in.readLine(str, maxLineLength)//只读到maxLineLength行
// in.readLine(str, maxLineLength, maxBytesToConsume)//这个构造方法来实现不清空,前面读取的行的值
if(linesize == 0)
return false;
// 通过分隔符'\t',将每行的数据解析成数组 pieces
String[] pieces = line.toString().split("\t");//因为,我们这里是。默认读完读到文件末尾。line是Text类型。pieces是String[],即String数组。
if(pieces.length != 5){
throw new IOException("Invalid record received");
}
int a,b,c;
try{
a = Integer.parseInt(pieces[2].trim()); //粉丝数,//将String类型,如pieces[2]转换成,float类型,给a
b = Integer.parseInt(pieces[3].trim()); //关注数
c = Integer.parseInt(pieces[4].trim()); //微博数
}catch(NumberFormatException nfe){
throw new IOException("Error parsing floating poing value in record");
}
//自定义key和value值
lineKey.set(pieces[0]); //完成自定义key数据
lineValue.set(a, b, c); //完成自定义value数据
// 或者写
// lineValue.set(Integer.parseInt(pieces[2].trim()),Integer.parseInt(pieces[3].trim()),Integer.parseInt(pieces[4].trim()));
return true;
}
@Override
public void close() throws IOException { //关闭输入流
if(in != null){
in.close();
}
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException { //获取当前的key,即CurrentKey
return lineKey; //返回类型是Text,即Text lineKey
}
@Override
public WeiBo getCurrentValue() throws IOException, InterruptedException { //获取当前的Value,即CurrentValue
return lineValue; //返回类型是WeiBo,即WeiBo lineValue
}
@Override
public float getProgress() throws IOException, InterruptedException { //获取进程,即Progress
return 0; //返回类型是float,即float 0
}
}
}
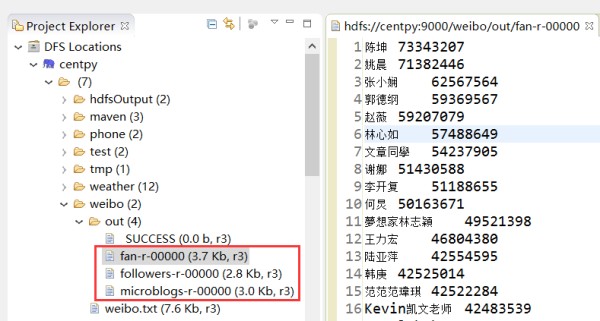
实验结果
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
网址:Hadoop实战:微博数据分析 https://mxgxt.com/news/view/137342
相关内容
如何高效进行微博舆情分析?揭秘行业内的实战技巧与工具粉丝数据分析
微博怎么查看明星数据分析 如何查看微博明星的流量热度
微博粉丝趋势分析 分析微博粉丝
大数据的舆情分析
明星数据分析怎么查
数据分析模型
虚拟服装大数据分析
微博明星新社交商业模式中的数据能力提效
一次微博数据挖掘试验:鹿晗粉丝的七张画像
随便看看
最新实时动态
- 老辈子们有点恨海情天全报应在小辈身上了,侯明昊 艾米 何润东 雀骨
- 最后的遗憾,真令人窒息
- Fanatics在纽约的活动中,Tom Brady怒扇Logan Paul,唐斯劝架
- 七旬老人硬核传宗接代,却遭遇更硬核的妹子 屏住呼吸
- 小太阳少年治愈满身伤痕的暗黑少女,双向救赎太好嗑!
- 刘宇宁 ,过后反被路人怼!原本欢乐的气氛瞬间尴尬!微博VC计划
- 每年夏天怎么能少脱口秀呢?! 《喜剧之王单口季》太值得 推荐了
- 雍正王朝笑面虎的獠牙,图里琛的高光封神局
- 郝熠然迎着光,活力满满开启新的一天
- 譚詠麟 : 想將來
热点实时动态
- 130636
- 25463
- 20060
- 19750
- 19497
- 19457
- 19189
- 18757
- 18738
- 18708

