基于多视频的3D面部重建与实时跟踪技术
“ 感知技术 · 感触CG · 感受艺术 · 感悟心灵 ”
中国很有影响力影视特效CG动画领域自媒体
这月适合学习。
为了带着我亲爱的小伙伴共同进步,特意为大家准备了点干货。

人生短暂,此时不学,更待何时。别慌,没疯、也没接广,就是觉得最近都是分享作品,是时候给大家换换口味了。
今天准备给大家介绍的是一项名为SPARK的新技术,可以通过分析多段视频,重建一个高度真实的3D面部模型,同时能够实时精确捕捉人脸的几何结构和外观特征。
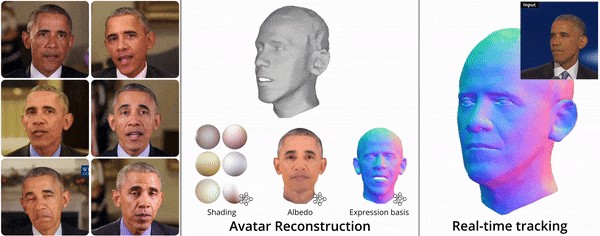
当前的3D人脸重建技术,可以通过分析海量人脸图像数据,实时生成适用于各种人物、光线环境以及面部姿势的3D面部模型。但普遍存在精度不足的问题,难以满足老化模拟、逼真面部替换等需要高度精确重建的应用领域。
而SPARK巧妙结合了传统计算机视觉技术和最新的深度学习方法,可以更快速、更准确生成能够适应不同姿势、表情和光照条件的精细3D面部模型。

整个方法分为两个关键阶段:
第一阶段,专注于精细建模。首先从收集的视频中提取丰富的视觉信息,重构出一个极其详细的3D面部模型。这个模型不仅准确地还原了面部的几何结构,还保留了个体独特的外观特征。
第二阶段,重点在于提高模型的适应性和效率。通过结合预训练模型的优势和定制的个性化解码器,加上针对性的迁移学习和精确的图像形成模型,提升了系统在特定个体面部捕捉和重建上的表现,特别是面部表情和姿势的精确度有了显著提升。
1
前期研究工作
SPARK相关的前期研究工作,主要分为两大类:
头像视频
许多研究都试图通过低成本的传感器来创建可动画化的3D头像,传统方法利用统计模型(通过分析大量数据来建立一个能够代表某一类对象的概率分布或特征描述)来重建3D形状和外观,但效果较为粗糙。
近期,如NerFACE、IMavatar、PointAvatar等研究,使用NeRF(动态神经辐射场)和隐式表面等技术,来提高重建质量。最近的FLARE能够在15分钟内构建高质量网格头像,并将头像的外观属性(如表面的颜色、纹理和光照)进行精确的分离和建模。
SPARK的团队在FLARE方法的基础上进行了改进和发展,即使用单摄像头拍摄的多个视频来重建高质量的3D头像,并通过技术改进来提高重建的效率和表现力。
单摄像头3D人脸捕捉
无模型的方法可以直接学习推断网格,但需要大量3D训练数据,且在合成与真实数据之间可能存在差距。3DMM等方法可以拟合到图像,但不适合实时应用。而近年来,基于深度学习的模型提供了稳定且快速的推理,但在表面泛化和对齐方面仍存在问题。
为了克服这些问题,SPARK通过使用单摄像头拍摄的多个视频来重建这些面部模型,引入改进措施,提高3D面部模型在实际应用中的表现力和保真度。
2
方法
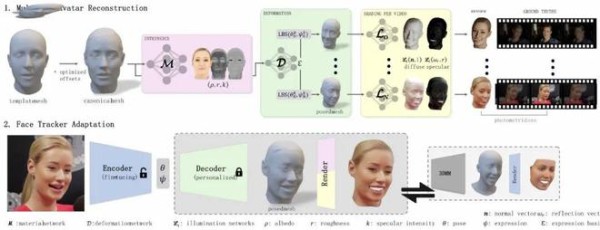
2.1 MultiFLARE:基于多个视频的3D面部重建方法
通过分析同一个人在多个视频中的面部表现,来重建出目标人物的3D面部模型。整个优化过程包含以下几个关键点:
几何建模:
使用三角网格来表示面部的3D结构。
基于FLAME通用人脸模型,对每个人的脸型进行个性化调整。
训练神经网络来学习个人特有的表情变化。
通过重新网格化,增加几何细节来提高分辨率。
光照处理:
因为视频可能在不同光照环境下拍摄,所以需要分别预测每个视频的光照条件。
使用神经分裂求和近似计算来模拟复杂的光照效果,为每个视频优化光照参数,以适应不同的光照条件。
材质属性:
使用神经网络来学习脸部不同位置的材质属性,如肤色、光泽度等。
假设个体的基本面部材质在不同视频间保持一致,只是光照不同。
通过组合材质和光照来计算最终颜色,以便在不同视频中保持一致外观。
渲染与优化:
将几何、光照和材质信息结合,用可微分渲染技术生成图像。
通过比较生成的图像和真实视频帧,不断调整模型参数,使重建结果更准确。
2.2 改进面部追踪器
目标是改进现有的3D面部重建系统,以便更好地适应特定个体的面部特征。
利用现有技术优势:
现有的3D面部重建网络(神经网络模型)已经通过大量训练,能够很好地处理不同光照、姿势和表情的情况。
SPARK团队在保留这种通用能力的同时,提高对特定个体面部特征的准确性。
个性化模型:
团队在MultiFLARE阶段,已经创建了独特的面部几何模型和材质属性。
但这些个性化模型与标准3D人脸模型(如FLAME)有所不同,直接在现有系统中替换标准模型会导致效果不佳。
适应性调整方案:
最终团队决定调整现有网络的部分结构,使其输出能够更好地匹配个性化模型。更新了网络后端的一些层(Residual Network Block和Multilayer Perceptron Head),同时保持前端层不变。
目的是保留网络识别一般面部特征的能力,同时调整对特定个人特征的理解。
平衡通用性和个性化:
允许在保持网络对各种面部表情和姿势的通用理解的同时,提高它对特定个人独特特征的识别能力。
通过这些方法,在保留一般特征的同时,提高重建特定个体面部特征的准确性。
2.3 训练细节
2.3.1 MultiFLARE
a)FLAME正则化
使用FLAME模型的一个特性,即“最邻近顶点”的值来正则化变形,来确保3D面部模型的变形(表情变化)是合理的,这一方法适用于任何网格拓扑和几何表示。
初始几何形状使用了FLAME模型的拓扑结构,在训练过程中对初始结合形状进行重新网格化,来增加细节和分辨率。之后将新的定点位置映射回原始网格,使用重心插值(Barycentric interpolation)来更新FLAME表情基。
b) 目标函数
完整的目标函数包括多个损失项(Loss Terms),以确保模型在不同方面表现良好。

同时,为了平衡不同损失项的重要性,还为每个损失项设定了相应的权重。
c )单阶段训练:
联合优化:在单个阶段联合优化标准位置、变形、材质和光照网络。
哈希编码:使用渐进式的多分辨率哈希编码,逐步启用更高分辨率的哈希级别,以防止过拟合(Overfitting)。
学习率衰减:对标准顶点的学习率进行衰减,每次迭代的衰减速率为 = 0.998 α=0.998。
微调参数:同时微调预估计的姿态和表情参数,以允许在预估计值不准确的情况下更好地对齐。
2.3.2 面部追踪器适应
a)目标函数:目标函数包含多个损失项,以确保面部追踪器能够更好地适应个性化几何模型。
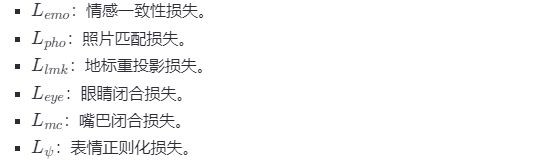
每个损失项都有相应的权重,以平衡不同损失项的重要性。
b)迁移学习:
调整编码器:调整编码器的权重,使其输出适应新的个性化几何表示。
个性化几何模型:使用个性化几何模型结合个性化的反射函数,并使用对应的光照参数进行计算。
通过这些详细的训练,使得SPARK能够在不同条件下更好地重建和追踪特定个体的面部特征。
2.4 推理时的预测
对于任何一张没见过的图像,SPARK使用适应后的编码器从图像中推断出一组参数,与预先计算好的个性化几何模型相结合。由于个性化几何模型已经在训练阶段预先计算好了,所以这个过程可以在标准GPU上实时完成。
3
实验
实验阶段,SPARK团队在六个不同主体的数据集上进行了演示。每个数据集包含6~12段视频,长度从10秒到1分钟不等,涵盖了采访、演讲和对话场景。
视频以1:4的比例进行子采样,并调整到适合训练的512×512分辨率,同目前最先进的前馈面部捕捉(Feedforward Facial Capture)方法进行比较,为了公平,团队还对另一个基准方法(EMOCA)进行了微调,以便在相同的条件下进行评估。
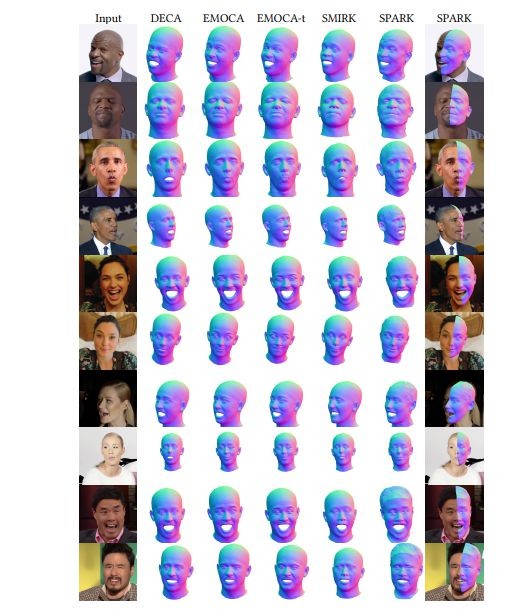
3.1定性评估
SPARK首先使用MultiFLARE重建头部头像,利用单摄像头拍摄的多个视频,分离脸部的漫反射率与阴影,恢复精细的几何细节。此外,改进的变形网络能够捕捉精确微妙的表情变化,提高重建的准确性。


在个性化实时面部捕捉测试阶段, SPARK可以实时重建给定面部以前未出现过的3D几何结构。
跟现有的方法比起来,SPARK能够更好地重建和输入图像匹配的面部模型,捕捉如张嘴情况下的皮肤褶以及和脸颊运动时的细微动态细节。即使是在不同的光照和姿态下,也依旧表现出色。
3.2定量评估
现有的面部捕捉方法,通常不对重建的3D面部姿态和表情的准确性进行评估。当前常见的做法是使用3D真实数据来评估中性脸的重建精度,没有包含同一人在不同场景下的多个视频,同时每帧都有3D真实数据的评估数据集。即使是最新的地标预测模型也不够密集,无法进行准确评估。
为了更准确地进行评估,SPARK引入了两个新的指标:
语义IoU指标:使用先进的语义分割方法来标注脸部的不同区域,比较重建的图像和真实图像中不同区域的匹配情况。
图像变形指标:从视频中选取图像,通过比较重建图像和真实图像之间的差异来评估几何跟踪的准确性。
4
局限性和未来发展
当然,作为新技术SPARK仍然存在着一定的局限性,尤其是在处理遮挡和面部配饰(如眼镜)方面。此外,在处理大面积胡子和长发时也有一定限制,尽管已经解决了部分问题,但在极端姿态和严重遮挡的情况下还是会出现一些错位。而简化渲染方程的集成,导致难以建模锐利的镜面高光和生硬的阴影,也一定程度影响了个性化外观模型的准确性。
未来还会进一步完善个性化方案,通过建模每个视频序列中的外观变化,增强SPARK的适用范围,以及在不同场景下的稳定性。
SPARK能够通过多个视频,实现实时重建完美匹配表情、姿态的3D面部模型。随着未来的不断优化,相信不久之后就能在视效等领域大展拳脚了~
蜘蛛精四妹,六妹来了!《黑神话:悟空》最新解禁图第三弹!
这是实拍的吧?3D?真人?傻傻分不清楚…
网址:基于多视频的3D面部重建与实时跟踪技术 https://mxgxt.com/news/view/1167869
相关内容
技术型小仵作运用3D头骨重建技术,再现了逝去母亲的面容, 御赐小仵作孩子指导明星3d建模的视频,孩子指导明星3d建模的视频怎么做
法国推出新型3D远程空中监视雷达,可同时跟踪低空和高空目标
江苏3d虚拟偶像出道视频制作 元腾火艳数智科技供应价格
关于明星幕后3d建模的信息
揭秘央视网新晋“虚拟小编”的诞生!集成大量AI技术,高精度3D人像建模
当虹科技董秘回复:元宇宙在众多场景下的传输核心载体是视频,当虹的核心技术团队专注于视频20多年,在VR编码、超高清视频编码技术上有较深的积累,参与国家广播电视总局科技司颁布的《5G高新视频
沸腾时刻发布智能健身镜明星版,全身3D动作追踪
三维空间重建(临云镜)重磅发布,30分钟体验AI构建的3D空间
LiveVideoStackCon 2023音视频技术大会上海站
随便看看
最新实时动态
- 她们遇到于妈之前明明是天选古人,后期为啥被硬生生带跑偏了!
- 《雀骨》结局藏满Callback,最后一个你发现了吗?
- 穆祉丞1分钟销售额破千万,穆祉丞发文回应爽爽爽
- 权志龙 韩国男艺人服兵役有多可怕?
- 难怪刘品言巅峰时突然消失了四年,原来是被流言逼的出国读书了!
- 中国女子记录和尼日利亚老公的幸福生活,目前已经怀孕了
- 黄明昊FIRST青年电影展晚宴路透 又萌又帅的推荐人 活力满满 青春感溢出屏幕
- 李东海台北FENDI站台,漫不经心拍手撩人
- 别人谈恋爱都双向奔赴,我的脸盲少主却单向脑补情深
- 第36届青岛国际啤酒节西海岸会场艺术巡游精彩上演
热点实时动态
- 136480
- 25503
- 20096
- 19786
- 19530
- 19487
- 19223
- 18792
- 18771
- 18744

