计算机大数据毕业设计推荐:基于大数据的音乐人社交媒体粉丝数据的可视化分析系统【python+Hadoop+spark】【前后端全栈、数据分析、python毕设项
作者:计算机编程小咖 个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 想说的话:感谢大家的关注与支持! 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目
@TOC
基于大数据的音乐人社交媒体粉丝数据的可视化分析系统介绍
《基于大数据的音乐人社交媒体粉丝数据的可视化分析系统》是一个面向现代音乐产业数据分析需求的综合性平台,其核心目标在于将海量、多维的社交媒体粉丝数据转化为直观、可洞察的商业价值。在技术架构上,本系统采用了先进的分布式处理框架与前后端分离的设计思想。数据处理核心强力依赖大数据生态,利用Hadoop的分布式文件系统(HDFS)作为海量数据的可靠存储基石,并引入高性能的内存计算框架Spark,通过其Spark SQL模块对结构化数据进行高效的即席查询与复杂分析。后端服务层基于Java语言栈,整合了主流的Spring Boot、Spring MVC及MyBatis框架,构建了稳定、可扩展的RESTful API接口,负责业务逻辑处理、数据调度与持久化操作,所有数据均存储于关系型数据库MySQL中。前端则采用Vue.js作为核心MVVM框架,配合ElementUI组件库快速构建美观且统一的用户界面,并深度集成Echarts图表库,将后端分析出的复杂数据结果以动态、交互式的图表(如柱状图、饼图、地理热力图等)形式呈现在数据大屏与各个分析模块中,实现了卓越的数据可视化效果。在功能层面,系统除了提供基础的用户管理、权限控制、系统公告等后台管理功能外,其核心价值体现在强大的数据分析与可视化能力上,包括:对粉丝总数、增长率等关键指标进行宏观监控的数据大屏;支持对原始数据进行增删改查的音乐媒体粉丝数据管理;通过时间序列分析预测作品流行趋势的音乐热度分析;直观展示粉丝地理位置分布的粉丝地域分析;利用算法为用户打上多维度标签的粉丝画像分析;以及将粉丝群体进行精准划分以便进行定向策略研究的粉丝分群分析。综上所述,本系统成功地将Hadoop、Spark等大数据技术与现代Web技术相结合,打造了一个从数据存储、处理到最终分析与可视化呈现的全链路解决方案,为深度挖掘音乐人粉丝经济的内在规律提供了强有力的技术支撑。
基于大数据的音乐人社交媒体粉丝数据的可视化分析系统演示视频
演示视频
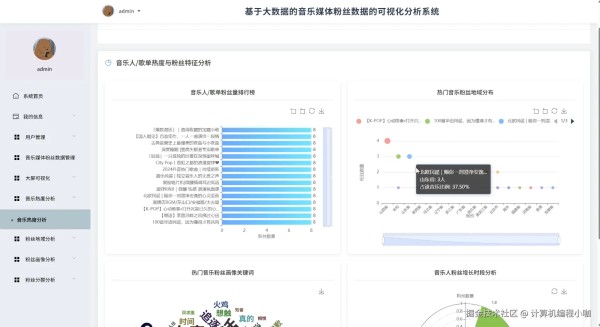
基于大数据的音乐人社交媒体粉丝数据的可视化分析系统演示图片
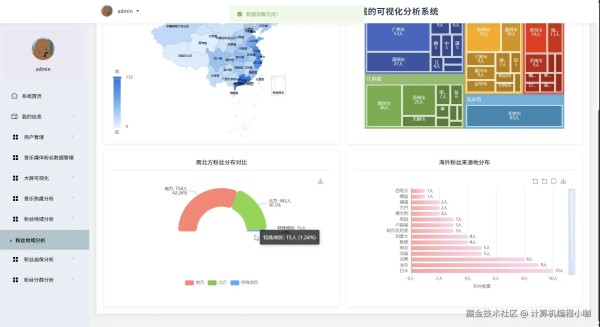
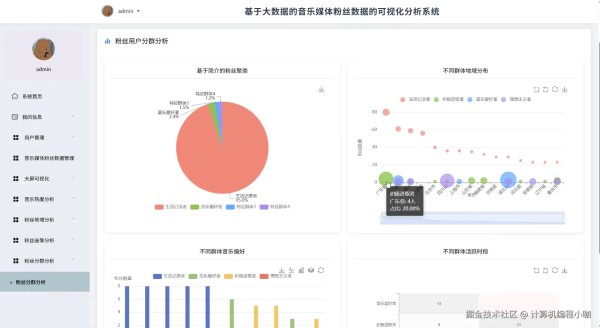
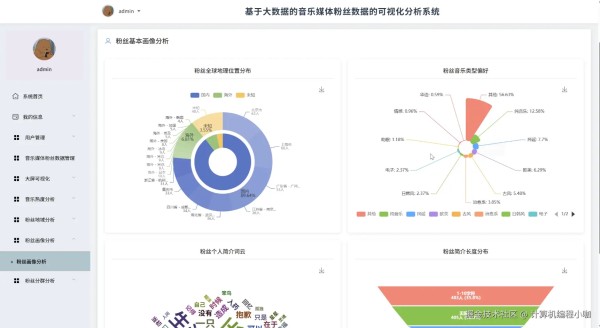

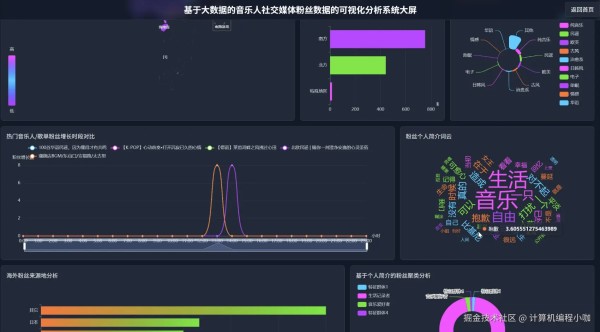
基于大数据的音乐人社交媒体粉丝数据的可视化分析系统代码展示
// 核心:构建或获取一个SparkSession实例,这是所有Spark操作的入口点 SparkSession spark = SparkSession.builder() .appName("MusicFanDataAnalysis") .master("local[*]") // 在本地模式下运行,实际部署时会指向YARN或Spark Master .config("spark.sql.warehouse.dir", "/user/hive/warehouse") .getOrCreate(); // --- 核心功能一:音乐热度分析 (analyzeMusicHeat) --- // 假设数据源为HDFS路径下的CSV文件,字段:musicId, userId, interactionType, createTime Dataset<Row> rawInteractionsDF = spark.read().option("header", "true").csv("hdfs://namenode:9000/data/music_interactions"); // 使用Spark SQL的DSL风格进行数据转换和计算,增加代码可读性和类型安全 // 1. 将时间戳字符串转换为日期格式,以便按天聚合 Dataset<Row> interactionsWithDateDF = rawInteractionsDF.withColumn("interactionDate", to_date(col("createTime"))); // 2. 定义一个加权热度值:分享=3分,评论=2分,点赞=1分 Dataset<Row> weightedInteractionsDF = interactionsWithDateDF.withColumn("heatScore", when(col("interactionType").equalTo("share"), 3) .when(col("interactionType").equalTo("comment"), 2) .when(col("interactionType").equalTo("like"), 1) .otherwise(0) // 其他互动类型不计分 ); // 3. 按音乐ID和互动日期进行分组 RelationalGroupedDataset groupedByMusicAndDate = weightedInteractionsDF.groupBy("musicId", "interactionDate"); // 4. 聚合计算每日的总热度分数 Dataset<Row> dailyHeatDF = groupedByMusicAndDate.agg( sum("heatScore").as("totalHeatScore"), count("*").as("interactionCount") ); // 5. 为了前端展示,按日期和热度进行排序 Dataset<Row> finalHeatResultDF = dailyHeatDF.orderBy(col("interactionDate").asc(), col("totalHeatScore").desc()); // 6. 将最终结果转换为JSON字符串格式,方便API返回给前端 // collectAsList()会将所有数据拉到Driver内存,对于大数据集需要谨慎,此处为示例 List<String> heatJsonList = finalHeatResultDF.toJSON().collectAsList(); System.out.println("音乐热度分析完成,共处理 " + finalHeatResultDF.count() + " 条聚合结果。"); // --- 核心功能二:粉丝地域分析 (analyzeFanRegion) --- // 假设数据源为HDFS路径下的parquet文件,字段:userId, userName, province, city Dataset<Row> fansProfileDF = spark.read().parquet("hdfs://namenode:9000/data/fan_profiles"); // 1. 过滤掉地域信息不明确或为空的记录,保证数据质量 Dataset<Row> validRegionFansDF = fansProfileDF.filter(col("province").isNotNull().and(col("province").notEqual(""))); // 2. 缓存中间结果,后续计算可复用,提高性能 validRegionFansDF.cache(); // 3. 计算粉丝总数,用于后续计算各省份占比 long totalFanCount = validRegionFansDF.count(); // 4. 按省份(province)进行分组 RelationalGroupedDataset groupedByProvince = validRegionFansDF.groupBy("province"); // 5. 聚合计算每个省份的粉丝数量 Dataset<Row> provinceCountDF = groupedByProvince.count().withColumnRenamed("count", "fanCount"); // 6. 计算每个省份的粉丝数占总粉丝数的百分比 // 注意:为避免整数除法,需要将其中一个数转为double类型 Dataset<Row> provinceStatDF = provinceCountDF.withColumn("percentage", col("fanCount").cast("double").multiply(100.0).divide(totalFanCount) ); // 7. 对百分比结果进行格式化,保留两位小数 Dataset<Row> formattedProvinceStatDF = provinceStatDF.withColumn("percentageFormatted", format_number(col("percentage"), 2)); // 8. 按粉丝数量降序排列,方便前端展示Top N省份 Dataset<Row> finalRegionResultDF = formattedProvinceStatDF.orderBy(col("fanCount").desc()); // 9. 收集结果并准备返回 List<Row> regionRows = finalRegionResultDF.select("province", "fanCount", "percentageFormatted").collectAsList(); System.out.println("粉丝地域分析完成,粉丝遍布 " + finalRegionResultDF.count() + " 个不同省份。"); validRegionFansDF.unpersist(); // 及时释放缓存 // --- 核心功能三:粉丝画像分析 (analyzeFanPortrait) --- // 复用上面的粉丝信息数据源 fansProfileDF,假设包含字段:gender, birthYear // 1. 过滤掉性别或出生年份为空的记录 Dataset<Row> validPortraitDF = fansProfileDF.filter(col("gender").isNotNull().and(col("birthYear").isNotNull())); // 2. 计算粉丝的当前年龄 Dataset<Row> fansWithAgeDF = validPortraitDF.withColumn("age", year(current_date()).minus(col("birthYear"))); // 3. 根据年龄划分不同的年龄段,便于统计分析 Dataset<Row> fansWithAgeGroupDF = fansWithAgeDF.withColumn("ageGroup", when(col("age").leq(17), "17岁及以下") .when(col("age").between(18, 24), "18-24岁") .when(col("age").between(25, 30), "25-30岁") .when(col("age").between(31, 40), "31-40岁") .otherwise("40岁以上") ); // 4. 过滤掉年龄计算异常的记录(例如birthYear不合法导致age为负数) Dataset<Row> cleanFansWithAgeGroupDF = fansWithAgeGroupDF.filter(col("age").gt(0)); // 5. 按“年龄段”和“性别”两个维度进行分组 RelationalGroupedDataset groupedByPortrait = cleanFansWithAgeGroupDF.groupBy("ageGroup", "gender"); // 6. 聚合计算每个细分群体的人数 Dataset<Row> portraitCountDF = groupedByPortrait.count().withColumnRenamed("count", "fanCount"); // 7. 按年龄段和性别进行排序,使结果更有条理 Dataset<Row> finalPortraitResultDF = portraitCountDF.orderBy("ageGroup", "gender"); // 8. 将分析结果收集起来,用于业务层封装 String portraitJson = finalPortraitResultDF.toJSON().collectAsList().toString(); System.out.println("粉丝画像分析完成,生成了 " + finalPortraitResultDF.count() + " 个用户分群。"); // 在应用结束前,关闭SparkSession释放资源 spark.stop();
基于大数据的音乐人社交媒体粉丝数据的可视化分析系统文档展示

作者:计算机编程小咖 个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 想说的话:感谢大家的关注与支持! 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目
网址:计算机大数据毕业设计推荐:基于大数据的音乐人社交媒体粉丝数据的可视化分析系统【python+Hadoop+spark】【前后端全栈、数据分析、python毕设项 https://mxgxt.com/news/view/1985440
相关内容
hadoop 大数据毕业设计python+spark高考志愿填报推荐系统 高考用户画像系统 高考分数线预测系统 高考可视化 知识图谱 高考爬虫 计算机毕业设计 机器学习 深度学习 人工智能 数据可视化基于python的NBA球员数据可视化分析的设计与实现.docx
使用 Python 分析大规模社交网络数据
5款好用的大数据分析软件推荐!——九数云
Hadoop数据库如何支持社交媒体数据分析
基于Hadoop的明星社交媒体影响力数据挖掘平台:设计与实现
基于Python语言的微博网络数据可视化系统设计与应用
探索Taylor Swift粉丝数据:Python数据分析与可视化实战
Python编程实现Taylor Swift粉丝数据分析与可视化工具
社交媒体数据分析平台的设计与实现
随便看看
最新实时动态
- 雍正王朝,天不怕地不怕,就怕四爷叫回话
- 今天又可以看到这个聪明帅气的刘宇宁了
- 杨洋如夏天第一个冰淇淋,出走半生归来仍是白衬衫少年
- 檀健次还好意思说自己从来没输过!上来直接就输了!
- 迪丽热巴和周星驰拍戏十分放心
- 谁才是真正的理塘王,顶针X安乾镐
- 景甜 微博VC计划
- 檀健次 合作古装剧?万年不变的鞠式妆容又要来了吗?
- 迪丽热巴谈文艺工作者的使命
- 将海虾与小猫奇妙联结的创意者,堪称绝世奇才
热点实时动态
- 130535
- 25463
- 20060
- 19750
- 19497
- 19457
- 19189
- 18757
- 18738
- 18708

