社会网络分析及其Python实现(一)
社会网络分析(Social Network Analysis, SNA)在人类学、心理学、社会学、数学以及统计学等领域中发展起来,是综合运用图论、数学模型来研究社会行动者之间的关系或通过这些关系流动的各种有形或无形的东西,如信息、资源等,近年来逐渐成为一种热门的社会科学研究方法。社会网络分析旨在理解和揭示人际关系网络的结构、特征和演化规律。它借助于图论、统计学、计算机科学等多个学科的理论和技术,通过分析个体之间的连接关系和信息流动,揭示社会系统中的隐含规律和重要特征。社会网络分析的核心思想是将个体视为节点,他们之间的关系视为边,从而构建起整个社会网络的拓扑结构。社会网络分析的历史可以追溯到20世纪30年代的社会学研究,但其真正迅速发展起来是在20世纪70年代。随着计算机和互联网技术的发展,社会网络分析方法得到了广泛应用,并在学术界和实践中取得了重要进展。近年来,随着大数据和机器学习技术的兴起,社会网络分析在规模化数据处理和模型构建方面有了更多创新。
一、社会网络分析概述
社会网络分析揭示了人际关系网中的模式与结构,通过节点(个体)和边(关系)来描绘社交动态。它帮助我们理解信息如何在网络中传播,识别关键人物及其影响力,从而洞察社会现象的深层次原因。
1.1 社会网络中的要素在社会网络分析中,有一些重要的要素和概念,它们帮助我们理解社会网络的结构、特征和动态。以下是社会网络中的一些关键要素:
节点(Node): 节点是网络中的基本单元,代表个体、组织或其他实体。在社会网络中,节点可以是人、团体、公司、网站等,它们通过连接来相互联系。
连接(Edge): 连接是节点之间的关系或联系,也称为边。在社会网络中,连接可以表示各种关系,如友谊、合作、信息传播等。连接可以是双向的(例如,朋友关系)也可以是单向的(例如,追随关系)。
权重(Weight): 权重表示连接的强度或重要性。在一些社会网络中,连接可能具有不同的权重,表示不同程度的关系紧密程度、资源交换等。权重可以用来衡量节点之间的关系强度。
网络密度(Network Density): 网络密度是指网络中实际连接数与可能连接数之比。高密度网络表示节点之间的连接较为紧密,低密度网络表示节点之间的连接较为稀疏。网络密度可以反映网络的紧密程度和信息传播的效率。
中心性(Centrality): 中心性是衡量节点在网络中重要性和影响力的指标。常见的中心性指标包括度中心性、接近中心性、介数中心性和特征向量中心性等,它们用来确定节点在网络中的位置和影响力程度。
社团(Community): 社团是网络中紧密连接的子群体,其中的节点之间具有较高的内部连接强度,而与其他社团之间的连接较弱。社团在网络中可以代表共同的兴趣、背景、行业等。
结构洞(Structural Hole): 结构洞是指网络中连接不同社团的节点或子群体,他们可以在不同的社团之间传播信息和资源,具有架起桥梁的作用。Burt的结构洞理论认为,掌握结构洞的个体在信息传播、创新和影响力方面具有优势。
社会资本(Social Capital): 社会资本是个体或群体通过社会关系所拥有的资源,包括信息、支持、信任等。Lin的社会资本理论强调了社会网络对个体和组织的价值,以及社会关系对于资源获取、创新和成功的重要性。
社会网络分析的应用潜力和多样性是令人惊叹的,以下是一些主要领域:
社交网络分析:社交网络分析是社会网络分析中最为人熟知的领域之一,主要关注在线社交网络中的用户行为、关系和信息传播。应用包括:
组织网络分析:组织网络分析关注组织内部成员之间的关系和信息流动,揭示组织的结构和运作方式。应用包括:
组织结构分析: 分析组织内部的连接关系和层级结构,了解组织的权力中心、信息流动路径和决策机制,为组织设计和管理提供参考。 团队合作研究: 研究团队成员之间的协作模式和信息交流,发现团队内部的协作障碍和优化空间,提高团队绩效和创新能力。 知识管理和转移: 通过分析组织内部的知识流动和知识共享情况,优化知识管理策略,促进知识转移和创新。影响力分析:影响力分析旨在识别社会网络中的关键节点和领袖人物,了解他们在信息传播和意见影响中的作用。应用包括:
领导者识别: 通过分析社会网络结构和信息传播模式,识别具有较高影响力和领导力的节点和个体,为领导力培养和选拔提供参考。 舆论引导: 通过选择合适的社交网络节点或个体进行信息传播和舆论引导,影响社会舆论和公众意见,推动特定议题或产品的传播和接受。 意见领袖挖掘: 通过监测社交网络中的话题和讨论,发现具有一定影响力和专业知识的意见领袖,为品牌营销和公关策略提供参考。犯罪网络分析:犯罪网络分析利用社会网络分析方法来追踪犯罪团伙的组织结构和活动路径,辅助犯罪调查和打击。应用包括:
犯罪网络识别: 通过分析犯罪分子之间的联系和交易模式,识别犯罪网络的关键成员和组织结构,为犯罪打击和预防提供线索。 犯罪活动预测: 基于犯罪网络的演化规律和行为模式,预测犯罪活动的发生时间、地点和形式,提前采取预防和打击措施。 犯罪证据收集: 通过监测和分析犯罪分子在社交网络和通讯平台上的活动,收集犯罪证据和线索,为案件侦破提供支持。健康行为分析:健康行为分析关注人们在健康相关决策和行为中的社会网络影响,例如吸烟、饮食和锻炼行为的传播。应用包括:
健康信息传播: 通过社交网络传播健康知识、宣传健康活动,促进健康行为的养成和传播。 疾病监测和预防: 通过分析社交网络中的健康行为数据和用户交流,监测疾病传播路径和风险因素,提出针对性的预防措施。 行为干预和治疗支持: 基于社交网络分析结果,设计个性化的健康行为干预方案,提供社群支持和治疗指导,帮助用户改善健康行为和生活方式。上述展示了社会网络分析在不同领域的广泛应用,它的影响力正在不断扩大,为解决复杂社会问题提供了新的视角和方法。 1.3 社会网络分析的优缺点 优点 缺点 深入洞察社会结构: 社会网络分析能够深入洞察社会结构和人际关系的细微变化,揭示人们之间的联系和互动模式。通过分析网络中的节点和边的连接关系,可以发现隐藏在背后的社会结构和规律,为社会研究提供新的视角和方法。 数据收集和处理难度: 社会网络分析需要大量的数据支持,包括人际关系数据、行为数据等。然而,获取这些数据并进行清洗、整理和分析是一项复杂而费时的工作,需要克服数据收集和处理的难度。 预测和干预能力: 社会网络分析可以预测信息传播路径、群体行为趋势和社会变化模式,帮助决策者制定更加有效的政策和干预措施。通过识别关键节点和影响力人物,可以有针对性地进行信息传播和舆论引导,影响社会舆论和公众行为。 隐私和伦理问题: 社会网络分析涉及到个人和组织的敏感信息,包括个人隐私、商业机密等。因此,需要严格遵守隐私保护和伦理规范,保护被研究对象的合法权益和隐私。 跨学科应用: 社会网络分析方法具有跨学科的特点,适用于各种领域的研究和应用,包括社会科学、管理学、医学、安全领域等。它可以帮助解决复杂的社会问题,促进不同领域的交叉合作和创新发展。 局限性: 社会网络分析方法可能无法捕捉到一些非正式的、暂时性的关系,例如隐性的社会联系和短期的互动行为。因此,在解释社会现象时存在一定的局限性,需要结合其他方法进行分析和验证。 发现潜在价值: 社会网络分析可以帮助发现潜在的社会资源和价值,识别具有影响力和潜力的个体和组织,为合作伙伴选择、资源配置和创新发展提供参考。 网络结构演化: 社会网络是动态变化的,其结构和成员关系会随着时间和环境的变化而发生演化。因此,需要不断更新和调整分析模型,以适应社会网络的变化和发展。 数据驱动决策: 社会网络分析基于大量的实际数据和统计方法,能够为决策者提供客观、科学的数据支持,帮助他们做出基于证据的决策和行动计划。 样本偏差: 社会网络分析可能受到样本偏差的影响,即研究样本不够代表性或不完整,导致分析结果失真或不准确。因此,需要采取合适的采样方法和数据校正技术,减少样本偏差对分析结果的影响。
二、社会网络分析指标
2.1 社会网络分析的分析角度社会网络分析法可以从多个不同角度对社会网络进行分析,包括中心性分析、凝聚子群分析、核心—边缘结构分析以及结构对等性分析等,这里仅介绍常用的前3种。
中心性分析:“中心性”是社会网络分析的重点之一。个人或组织在其社会网络中具有怎样的权力,或者说居于怎样的中心地位,这一思想是社会网络分析者最早探讨的内容之一。个体的中心度(Centrality)测量个体处于网络中心的程度,反映了该点在网络中的重要性程度。因此一个网络中有多少个行动者/节点,就有多少个个体的中心度。除了计算网络中个体的中心度外,还可以计算整个网络的集中趋势(可简称为中心势)(Centralization)。与个体中心度刻画的是个体特性不同,网络中心势刻画的是整个网络中各个点的差异性程度,因此一个网络只有一个中心势。根据计算方法的不同,中心度和中心势都可以分为3种:点度中心度/点度中心势,中间中心度/中间中心势,接近中心度/接近中心势。
凝聚子群分析:当网络中某些行动者之间的关系特别紧密,以至于结合成一个次级团体时,这样的团体在社会网络分析中被称为凝聚子群。分析网络中存在多少个这样的子群,子群内部成员之间关系的特点,子群之间关系特点,一个子群的成员与另一个子群成员之间的关系特点等就是凝聚子群分析。由于凝聚子群成员之间的关系十分紧密,因此有的学者也将凝聚子群分析形象地称为“小团体分析”。
核心-边缘结构分析:核心—边缘(Core-Periphery)结构分析的目的是研究社会网络中哪些节点处于核心地位,哪些节点处于边缘地位。核心边缘结构分析具有较广的应用性,可用于分析精英网络、科学引文关系网络以及组织关系网络等多种社会现象中的核心—边缘结构。
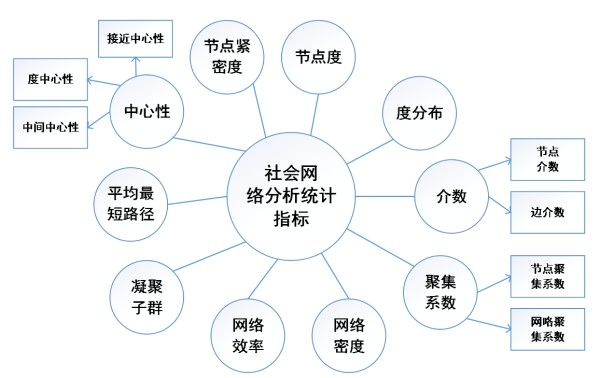
社会网络分析指标是用来描述和量化社会网络结构、节点特征、关系特征等的各种度量和指标。这些指标帮助研究者理解网络的形态、特征和动态,进而揭示个体和组织在网络中的位置、影响力以及其它属性。以下是一些常用的社会网络分析统计指标:
节点度(Degree): 节点度是指一个节点与其他节点之间的连接数量。在有向网络中,分为入度和出度。节点度越高,表示该节点在网络中与其他节点有更多的连接。
中心性(Centrality): 中心性指标衡量了节点在网络中的重要性和影响力程度。常见的中心性指标包括:
度中心性(Degree Centrality): 节点的度数与网络中所有节点的最大度数之比。
接近中心性(Closeness Centrality): 衡量节点到达网络中其他节点的平均路径长度的倒数。接近中心性高的节点距离网络中其他节点更近,具有更高的中心性。
介数中心性(Betweenness Centrality): 衡量节点在网络中的“中介”程度,即节点在网络中连接其他节点的最短路径的数量。
特征向量中心性(Eigenvector Centrality): 衡量节点与网络中其他重要节点的连接程度,即节点连接到的节点的中心性之和。
群体结构(Clustering): 群体结构指标描述了网络中群体的聚集程度和结构。常见的指标包括:
聚类系数(Clustering Coefficient): 表示节点邻居之间存在连接的比率,用来度量节点所在群体的紧密程度。
传播路径长度(Path Length): 衡量网络中节点之间信息传播的距离,常用平均最短路径长度来描述。
社区发现(Community Detection): 社区发现指标用来发现网络中的子群体或社群,揭示网络的模块化结构和群体之间的关联。一些常用的社区发现方法包括模块度、谱聚类、Louvain算法等。
结构洞(Structural Hole): 结构洞理论由Burt提出,用来描述网络中连接不同社区的节点,这些节点通常具有信息传播和控制的优势。
社会资本(Social Capital): 社会资本理论关注个体和组织通过社会网络所获得的资源,一些指标包括:
关系密度(Relation Density): 描述了网络中关系的丰富程度,即节点之间的连接密度。
信任度(Trust): 描述了网络中节点之间的信任程度,即节点之间的关系质量。
这些指标提供了对社会网络结构和节点特征的量化描述,帮助研究者深入理解网络的形成、演化和影响力分配。在实际应用中,研究者可以根据具体问题选择合适的指标来分析和解释社会网络的特性和行为。
三、社会网络分析Python
3.1 网络中心度 度中心度(Degree Centrality):度中心度衡量了节点在网络中的连接数量。公式:Cdegree(v)=degree(v)N−1" role="presentation">Cdegree(v)=degree(v)N−1
其中,degree(v)" role="presentation">degree(v) 是节点 v" role="presentation">v 的度数,N" role="presentation">N 是网络中的节点数量。
介数中心度(Betweenness Centrality):介数中心度衡量了节点在网络中作为最短路径之间的中介程度。公式:Cbetweenness(v)=∑s≠v≠tσst(v)σst" role="presentation">Cbetweenness(v)=∑s≠v≠tσst(v)σst
其中,σst" role="presentation">σst 是节点 s" role="presentation">s 和 t" role="presentation">t 之间的最短路径数量,σst(v)" role="presentation">σst(v) 是通过节点 v" role="presentation">v 的最短路径数量。
接近中心度(Closeness Centrality):接近中心度衡量了节点到网络中其他节点的平均最短路径长度的倒数。公式:Ccloseness(v)=N−1∑u≠vd(v,u)" role="presentation">Ccloseness(v)=N−1∑u≠vd(v,u)
其中,d(v,u)" role="presentation">d(v,u) 是节点 v" role="presentation">v 到节点 u" role="presentation">u 的最短路径长度。
import networkx as nx def calculate_degree_centrality(G): return nx.degree_centrality(G) def calculate_betweenness_centrality(G): return nx.betweenness_centrality(G, normalized=True) def calculate_closeness_centrality(G): return nx.closeness_centrality(G) # 测试示例 G = nx.barabasi_albert_graph(100, 2) degree_centrality = calculate_degree_centrality(G) betweenness_centrality = calculate_betweenness_centrality(G) closeness_centrality = calculate_closeness_centrality(G) print("度中心度:", degree_centrality) print("介数中心度:", betweenness_centrality) print("接近中心度:", closeness_centrality) 3.2 网络中心势(Network Centrality)
网络中心势是基于网络结构的中心度指标,它考虑了节点的邻居节点对节点本身的影响。在有向图中,网络中心势可以通过计算节点的入度和出度以及邻居节点的中心度得到。
度数中心势(Degree Centrality Potential):度数中心势是节点的邻居节点的度中心度之和。公式:Cdegree(v)=∑u≠vCdegree(u)" role="presentation">Cdegree(v)=∑u≠vCdegree(u)
其中,Cdegree(u)" role="presentation">Cdegree(u)是节点 u" role="presentation">u 的度中心度。
接近中心势(Closeness Centrality Potential):接近中心势是节点的邻居节点的接近中心度之和的倒数。公式:Ccloseness(v)=(∑u≠vCcloseness(u))−1" role="presentation">Ccloseness(v)=(∑u≠vCcloseness(u))−1
其中,Ccloseness(u)" role="presentation">Ccloseness(u) 是节点 u" role="presentation">u 的接近中心度。
中介中心势(Betweenness Centrality Potential):中介中心势是节点的邻居节点的介数中心度之和。公式:Cbetweenness(v)=∑u≠vCbetweenness(u)" role="presentation">Cbetweenness(v)=∑u≠vCbetweenness(u)
其中,Cbetweenness(u)" role="presentation">Cbetweenness(u)是节点 u" role="presentation">u 的介数中心度。
import networkx as nx def calculate_degree_centrality_potential(G): degree_centrality = nx.degree_centrality(G) degree_centrality_potential = {} for node in G.nodes(): neighbors = set(G.neighbors(node)) node_potential = sum(degree_centrality[n] for n in neighbors) degree_centrality_potential[node] = node_potential return degree_centrality_potential def calculate_closeness_centrality_potential(G): closeness_centrality = nx.closeness_centrality(G) closeness_centrality_potential = {} for node in G.nodes(): neighbors = set(G.neighbors(node)) node_potential = sum(closeness_centrality[n] for n in neighbors) closeness_centrality_potential[node] = 1 / node_potential return closeness_centrality_potential def calculate_betweenness_centrality_potential(G): betweenness_centrality = nx.betweenness_centrality(G, normalized=True) betweenness_centrality_potential = {} for node in G.nodes(): neighbors = set(G.neighbors(node)) node_potential = sum(betweenness_centrality[n] for n in neighbors) betweenness_centrality_potential[node] = node_potential return betweenness_centrality_potential # 测试示例 G = nx.barabasi_albert_graph(100, 2) degree_centrality_potential = calculate_degree_centrality_potential(G) closeness_centrality_potential = calculate_closeness_centrality_potential(G) betweenness_centrality_potential = calculate_betweenness_centrality_potential(G) print("度数中心势:", degree_centrality_potential) print("接近中心势:", closeness_centrality_potential) print("中介中心势:", betweenness_centrality_potential) 3.3 度和度相关性 密度(Density):衡量网络中各个节点间的连接强度。将密度接近0的网络称为稀疏网络。公式D=2mn(n−1)​" role="presentation">D=2mn(n−1),其中 m" role="presentation">m 是连接数量,n" role="presentation">n 是节点数量。 同配性(Assortativity):同配性描述了网络中节点之间连接模式的倾向性,即度高的节点更倾向于连接到度也高的节点,或者度低的节点更倾向于连接到度也低的节点。公式r=∑jkjk(ejk−qjqk)σ2" role="presentation">r=∑jkjk(ejk−qjqk)σ2,其中r" role="presentation">r 是同配系数;j" role="presentation">j 和 k" role="presentation">k 分别是节点 j" role="presentation">j 和 k" role="presentation">k 的度;ejk" role="presentation">ejk 是节点j" role="presentation">j 和 k" role="presentation">k 之间的边的数量;qj" role="presentation">qj 和qk" role="presentation">qk分别是节点j" role="presentation">j 和 k" role="presentation">k 的度的比例;σ2" role="presentation">σ2是度的方差。同配系数r是一种基于度的皮尔逊相关系数。r" role="presentation">r是正值时,表示度大的节点倾向于连接度大的节点;r" role="presentation">r是负值时,表示度大的节点倾向于连接度小的节点;r" role="presentation">r=+1时,表示网络具有很好的同配性;r" role="presentation">r=-1时,表示网络具有很好的异配性。社交网络就表现出很明显的同配性;而科技网络,生物网络以及金融网络则表现出很强的异配性。
import networkx as nx # 创建图 G = nx.Graph() G.add_edges_from([(1, 2), (1, 3), (2, 3), (2, 4)]) # 计算网络密度 density = nx.density(G) print("网络密度:", density) # 计算同配性 assortativity = nx.degree_assortativity_coefficient(G) print("同配性:", assortativity) 3.4 距离和路径 直径(Diameter):直径是网络中任意两个节点之间的最长路径长度,表示网络的最大距离。公式 diameter=maxu,v∈Vd(u,v)" role="presentation">diameter=maxu,v∈Vd(u,v),其中 d(u,v)" role="presentation">d(u,v) 表示节点u" role="presentation">u到节点v" role="presentation">v的最短路径长度。 节点偏心率(Node Eccentricity):指网络中其他节点与某一节点之间的最长路径长度。公式eccentricity(v)=maxu∈Vd(u,v)" role="presentation">eccentricity(v)=maxu∈Vd(u,v),其中d(u,v)" role="presentation">d(u,v) 表示节点u" role="presentation">u到节点v" role="presentation">v的最短路径长度。 半径(Radius):网络中偏心率最小的节点对之间的距离,表示网络中最短路径的最大长度 维纳指数(Wiener Index):维纳指数是网络中所有节点对之间最短路径长度的总和。公式 W=∑u,v∈Vd(u,v)" role="presentation">W=∑u,v∈Vd(u,v)
网络全局效率(Global Efficiency):网络全局效率是网络中信息传播的效率,与节点间的平均距离成反比。公式 GE=1n(n−1)∑i≠j1d(i,j)" role="presentation">GE=1n(n−1)∑i≠j1d(i,j),其中 n" role="presentation">n是网络中节点的数量,d(i,j)" role="presentation">d(i,j)是节点 i" role="presentation">i 和节点 j" role="presentation">j 之间的最短路径长度。 网络平均一致估计(Mean Nodal Efficiency):网络平均一致估计是网络全局效率的倒数,表示网络中信息传播的平均效率。公式 MN=1GE" role="presentation">MN=1GE 平均路径长度:平均路径长度是衡量网络结构紧密程度的重要指标之一,它表示网络中任意两个节点之间的平均最短路径长度。公式L=1n(n−1)∑i≠jdij" role="presentation">L=1n(n−1)∑i≠jdij,其中L" role="presentation">L表示平均路径长度;n" role="presentation">n表示网络中节点的数量;dij" role="presentation">dij表示节点 i" role="presentation">i 到节点 j" role="presentation">j 的最短路径长度;求和是对网络中所有不同的节点对(i,j)" role="presentation">(i,j) 进行的。
import networkx as nx # 创建图 G = nx.Graph() G.add_edges_from([(1, 2), (1, 3), (2, 3), (2, 4)]) # 计算直径 diameter = nx.diameter(G) print("直径:", diameter) # 计算节点偏心率 eccentricity = nx.eccentricity(G) print("节点偏心率:", eccentricity) # 计算半径 radius = nx.radius(G) print("半径:", radius) # 计算维纳指数 wiener_index = nx.wiener_index(G) print("维纳指数:", wiener_index) # 计算网络全局效率 global_efficiency = nx.global_efficiency(G) print("网络全局效率:", global_efficiency) # 计算网络平均一致估计 mean_nodal_efficiency = 1 / global_efficiency print("网络平均一致估计:", mean_nodal_efficiency) # 计算平均路径长度 average_path_length = nx.average_shortest_path_length(G) print("平均路径长度:", average_path_length) 3.5 网络结构 聚类系数(Clustering Coefficient):网络聚类系数用于度量网络中节点的积聚情况。它表示一个节点的邻居之间实际存在的边数与可能存在的边数之间的比率。如果聚类系数趋近于1,说明节点的邻居之间几乎全部相连;如果聚类系数趋近于0,说明节点的邻居之间连接较为稀疏。公式 CC(v)=2⋅T(v)deg(v)⋅(deg(v)−1)" role="presentation">CC(v)=2⋅T(v)deg(v)⋅(deg(v)−1),其中 CC(v)" role="presentation">CC(v) 是节点v" role="presentation">v的聚类系数;T(v)" role="presentation">T(v)是节点v" role="presentation">v的邻居节点之间实际存在的边数;deg(v)" role="presentation">deg(v) 是节点v" role="presentation">v的度数。
局部聚类系数(Local Clustering Coefficient):局部聚类系数是网络中节点局部积聚的能力的量化指标。它是所有节点的聚类系数的平均值。公式CC=1n∑v∈VCC(v)" role="presentation">CC=1n∑v∈VCC(v),其中 n" role="presentation">n 是网络中节点的数量。 模块化系数(Modularity Coefficient):模块化系数用于度量网络中某一特定聚类的可能性,即度量网络中聚类的强度。它描述了网络中节点集中于特定社团的程度。公式 Q=12m∑i,j(Aij−kikj2m)δ(ci,cj)" role="presentation">Q=12m∑i,j(Aij−kikj2m)δ(ci,cj) 其中:Q" role="presentation">Q 是模块化系数;A_ij" role="presentation">A_ij是节点 i" role="presentation">i 和节点 j" role="presentation">j 之间的边的数量;ki" role="presentation">ki 和 kj" role="presentation">kj 分别是节点i" role="presentation">i 和节点j" role="presentation">j 的度;m" role="presentation">m是网络中边的总数;δ(ci,cj)" role="presentation">δ(ci,cj)是指示函数,当节点 i" role="presentation">i 和节点 j" role="presentation">j 属于同一个社团时为1,否则为0。
import networkx as nx # 创建图 G = nx.Graph() G.add_edges_from([(1, 2), (1, 3), (2, 3), (2, 4)]) # 计算网络聚类系数 clustering_coefficient = nx.average_clustering(G) print("网络聚类系数:", clustering_coefficient) # 计算局部聚类系数 local_clustering_coefficient = nx.clustering(G) average_local_clustering_coefficient = sum(local_clustering_coefficient.values()) / len(local_clustering_coefficient) print("局部聚类系数:", average_local_clustering_coefficient) # 计算模块化系数 modularity_coefficient = nx.algorithms.community.quality.modularity(G, nx.algorithms.community.greedy_modularity_communities(G)) print("模块化系数:", modularity_coefficient) 3.6 互惠性(Reciprocity):
计算公式:R={number of edges in both directions}{number of edges}" role="presentation">R={number of edges in both directions}{number of edges} 该指标表示网络中存在双向连接的边的比例。
import networkx as nx import matplotlib.pyplot as plt # 创建一个图对象 G = nx.Graph() # 添加节点和边 G.add_edges_from([('A', 'B'), ('A', 'D'), ('B', 'C'), ('B', 'D'), ('D', 'E'), ('E', 'D')]) reciprocity = nx.reciprocity(G) print("互惠性:", reciprocity) 3.7 介数(Betweenness Centrality):
介数衡量节点在网络中承担信息传递的程度,计算公式:
b(v)=∑s≠v≠tσst(v)σst" role="presentation">b(v)=∑s≠v≠tσst(v)σst
σst" role="presentation">σst是从节点 s" role="presentation">s 到节点 t" role="presentation">t 的最短路径数量,σst(v)" role="presentation">σst(v) 是通过节点v" role="presentation">v的最短路径数量。
import networkx as nx G = nx.Graph() # 添加节点和边 G.add_edges_from([('A', 'B'), ('A', 'D'), ('B', 'C'), ('B', 'D'), ('D', 'E'), ('E', 'D')]) betweenness_centrality = nx.betweenness_centrality(G) print("介数中心性:", betweenness_centrality) 3.8 度分布(Degree Distribution):
度分布描述了网络中节点的度数分布情况,通常用概率分布函数表示。无标度网络(Scale-Free Networks)是社会网络研究中的一个重要概念,其特点是网络中节点的度(连接数)分布满足幂律分布(Power-Law Distribution)。在这种网络中,少数节点拥有大量的连接,而大多数节点只有很少的连接。幂律分布的一般形式为:P(k)∼k−γ" role="presentation">P(k)∼k−γ,其中P(k)" role="presentation">P(k) 是具有 k" role="presentation">k 个连接的节点的概率,γ" role="presentation">γ是幂律指数。
import networkx as nx import matplotlib.pyplot as plt G = nx.Graph() # 添加节点和边 G.add_edges_from([('A', 'B'), ('A', 'D'), ('B', 'C'), ('B', 'D'), ('D', 'E'), ('E', 'D')]) degree_sequence = [d for n, d in G.degree()] degree_count = nx.degree_histogram(G) degrees = range(len(degree_count)) plt.bar(degrees, degree_count, width=0.80, color='b') plt.title("Degree Distribution") plt.ylabel("Frequency") plt.xlabel("Degree") plt.show() 3.9 K-核(K-Core)
核是网络中的一个子图,其中每个节点的度至少为 k" role="presentation">k,并且核中的所有节点都至少连接到其他核中的 k" role="presentation">k 个节点。
import networkx as nx G = nx.Graph() # 添加节点和边 G.add_edges_from([('A', 'B'), ('A', 'D'), ('B', 'C'), ('B', 'D'), ('D', 'E'), ('E', 'D')]) k_core = nx.k_core(G) print("K-Core子图:", k_core.nodes()) 3.10 小世界效应
小世界效应是指在许多真实网络中观察到的现象,即网络中的大多数节点之间可以通过相对较少的步骤互相到达。在复杂网络分析中,小世界效应通常通过计算网络的平均最短路径长度和随机网络(例如随机图)的平均最短路径长度来进行比较。小世界效应计算步骤:
计算原始网络的平均最短路径长度 Lreal" role="presentation">Lreal。
创建一个随机网络(例如随机图),保持节点数量和度分布与原始网络相同。
计算随机网络的平均最短路径长度 Lrandom" role="presentation">Lrandom。
比较实际网络和随机网络的平均最短路径长度,如果实际网络的平均最短路径长度接近于随机网络,那么网络具有小世界效应。
import networkx as nx import numpy as np def calculate_small_world_effect(G): # 计算原始网络的平均最短路径长度 L_real = nx.average_shortest_path_length(G) # 创建一个随机网络,保持节点数量和度分布与原始网络相同 G_random = nx.double_edge_swap(G, nswap=len(G.edges())*5, max_tries=len(G.edges())*10) # 计算随机网络的平均最短路径长度 L_random = nx.average_shortest_path_length(G_random) # 计算小世界效应指数 small_world_effect = L_real / L_random return small_world_effect # 创建一个图对象 G = nx.watts_strogatz_graph(100, 6, 0.1) # 使用 Watts-Strogatz 小世界模型创建一个图 # 计算小世界效应指数 small_world_effect = calculate_small_world_effect(G) print("小世界效应指数:", small_world_effect) 3.11 凝聚子群分析(Agglomerative Hierarchical Clustering)
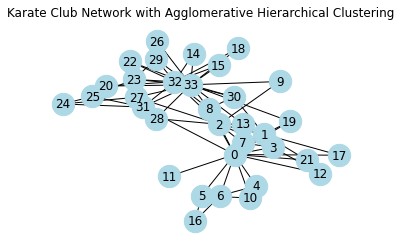
凝聚子群分析是一种常见的聚类算法,用于将节点分组成具有相似特征或连接模式的群组。在网络分析中,凝聚子群分析可以用于发现网络中的社区结构,即节点之间紧密连接的子图。该算法从每个节点开始,逐步合并具有相似连接模式的节点对,直到形成一组满足某些停止条件的子群。
import networkx as nx import matplotlib.pyplot as plt from networkx.algorithms.community import greedy_modularity_communities # 构建图(注意这里应该是karate_club_graph()而不是karate_club_graph) G = nx.karate_club_graph() # 执行凝聚子群分析 communities = list(greedy_modularity_communities(G)) # 创建一个新的图形和轴对象 fig, ax = plt.subplots() # 绘制结果 pos = nx.spring_layout(G) nx.draw(G, pos, with_labels=True, node_color='lightblue', node_size=500, ax=ax) ax.set_title('Karate Club Network with Agglomerative Hierarchical Clustering') plt.show() # 输出社区 print("Detected communities:") for idx, community in enumerate(communities): print(f"Community {idx + 1}: {community}")
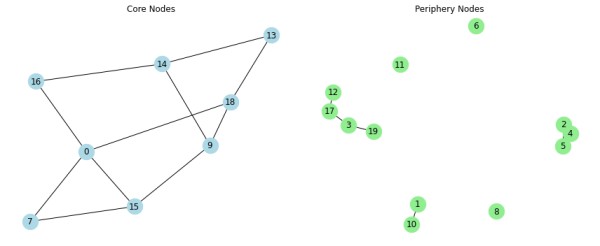
给定一个网络,我们可以根据节点的度来将节点划分为核心节点和边缘节点。通常情况下,节点的度高于某个阈值的节点被视为核心节点,而度低于该阈值的节点被视为边缘节点。
import networkx as nx import matplotlib.pyplot as plt def core_and_periphery_partition(G, threshold): core_nodes = [node for node, degree in G.degree() if degree >= threshold] periphery_nodes = [node for node, degree in G.degree() if degree < threshold] core_subgraph = G.subgraph(core_nodes) periphery_subgraph = G.subgraph(periphery_nodes) return core_subgraph, periphery_subgraph # 创建一个简单的网络 G = nx.erdos_renyi_graph(n=20, p=0.2) # 设置阈值 degree_threshold = 5 # 划分核心和边缘 core_subgraph, periphery_subgraph = core_and_periphery_partition(G, degree_threshold) # 创建一个图形和两个轴 fig, axs = plt.subplots(1, 2, figsize=(12, 5)) # 绘制核心子图 if core_subgraph.number_of_nodes() > 0: nx.draw(core_subgraph, ax=axs[0], with_labels=True, node_color='lightblue', node_size=500) axs[0].set_title('Core Nodes') else: axs[0].set_title('No Core Nodes to Display') axs[0].axis('off') # 隐藏空的子图坐标轴 # 绘制边缘子图 if periphery_subgraph.number_of_nodes() > 0: nx.draw(periphery_subgraph, ax=axs[1], with_labels=True, node_color='lightgreen', node_size=500) axs[1].set_title('Periphery Nodes') else: axs[1].set_title('No Periphery Nodes to Display') axs[1].axis('off') # 隐藏空的子图坐标轴 # 显示图形 plt.tight_layout() plt.show()
网络效率是一种衡量网络中信息传输效率的指标,它是指网络中节点之间信息传递的速度或效率。网络效率可以通过全局效率和局部效率来衡量。
全局效率(Global Efficiency):全局效率是网络中所有节点对之间最短路径的倒数的平均值。它表示了网络中信息传输的整体效率,是网络连通性的一个指标。公式: Eglobal=1n(n−1)∑i≠j1d(i,j)" role="presentation">Eglobal=1n(n−1)∑i≠j1d(i,j)其中:Eglobal" role="presentation">Eglobal是全局效率;n" role="presentation">n 是网络中节点的数量;d(i,j)" role="presentation">d(i,j)是节点 i" role="presentation">i和节点j" role="presentation">j之间的最短路径长度。
局部效率(Local Efficiency):局部效率是每个节点的局部最短路径的倒数的平均值。它表示了网络中每个节点作为信息传输中心的效率。公式: Elocal(i)=1ni(ni−1)∑j≠k≠i1d(j,k)" role="presentation">Elocal(i)=1ni(ni−1)∑j≠k≠i1d(j,k)其中:Elocal(i)" role="presentation">Elocal(i)是节点i" role="presentation">i 的局部效率;ni" role="presentation">ni是节点 i" role="presentation">i 的邻居节点的数量;d(j,k)" role="presentation">d(j,k) 是节点 j" role="presentation">j 和节点k" role="presentation">k 之间的最短路径长度。
import networkx as nx # 创建图 G = nx.Graph() G.add_edges_from([(1, 2), (1, 3), (2, 3), (2, 4)]) # 计算全局效率 global_efficiency = nx.global_efficiency(G) print("全局效率:", global_efficiency) # 计算每个节点的局部效率 local_efficiency = nx.local_efficiency(G) print("每个节点的局部效率:", local_efficiency)
总结
社会网络分析是一种跨学科的研究方法,通过分析人际关系网络的结构、特征和演化规律,揭示社会系统中的隐含规律和重要特征。其优点包括深入洞察社会结构、预测和干预能力强、跨学科应用广泛、发现潜在价值和数据驱动决策。然而,社会网络分析也面临数据收集和处理难度、隐私和伦理问题、局限性、网络结构演化和样本偏差等挑战。综合来看,社会网络分析为我们提供了深入理解人类社会行为和组织结构的重要工具,同时需要克服各种挑战,不断发展和完善其方法和应用。
参考文献
一文读懂社会网络分析(SNA)理论、指标与应用 社会网络分析图】python实现 复杂网络分析-个人笔记 总结 利用python绘制社会网络关系图(networks) [Network Analysis] 复杂网络分析总结(最后有数据)网址:社会网络分析及其Python实现(一) https://mxgxt.com/news/view/1926214
相关内容
如何用Python分析社交网络数据探索Python中的社交网络分析:构建社交网络应用
Python人物社交网络分析—平凡的世界
基于Python的社交网络分析与图论算法实践
如何使用Python进行社交网络分析
使用 Python 分析大规模社交网络数据
python绘制社交网络图
社交网络分析.ppt.ppt
Python 如何使用Python可视化社交网络
典型的社会网络分析软件工具及分析方法
随便看看
最新实时动态
- 再次败给阿根廷而强忍泪水的贝克汉姆,维多利亚和儿子一起安慰他!
- 陈蕾娜,世界国际旅游小姐中国总冠军,身高183,来自北京
- 这一段,小时候看的时候感觉老爽了
- 压力大时,看看侯明昊、艾米
- 没有完美犯罪,只有父母的爱永不缺席(2) 封神电影
- 小尼玛吓到为名好好笑
- 喜剧舞台上的灵魂炸裂,迪丽热巴用荒诞解构逻辑,把无厘头升华为艺术
- 刘涛林更新当面调侃潘玮柏,姐弟互动投喂吐槽
- 田栩宁多元视角实验大片
- 苏醒携舞团再度燃爆舞台,260711现场高能唱跳!
热点实时动态
- 128173
- 25461
- 20059
- 19744
- 19495
- 19452
- 19187
- 18756
- 18730
- 18706

