上一期的推送,小F做了一些社交网络分析的前期工作。
传送门: Python数据可视化:平凡的世界
比如获取文本信息,人物信息。
最后生成一个人物出现频数词云图。

本次来完成剩下的工作。
实现《平凡的世界》的人物社交网络分析。
/ 01 / 人物联系
人物社交网络分析是用来查看节点、连接边之间社会关系的一种分析方法。
节点是社交网络里的每个参与者,连接边则表示参与者之间的关系。
节点之间可以有很多种连接。
社交网络是一张地图,可以标示出所有与节点间相关的连接边。
社交网络也可以用来衡量每个参与者的“人脉”。
本次以《平凡的世界》为例,可视化其的人物关系。
两两人物关系有以下两种方式。
①两个人名同时出现在同一段落,则联系+1。
②两个人名同时出现在同一章节,则联系+1。
接下来利用之前获取的素材,生成数据包。
import os
# 打开文本
file_text = open('world1.txt')
file_name = open('name.txt')
# 人物信息
names = []
for name in file_name:
names.append(name.replace('\n', ''))
# 文本信息
content = []
for line in file_text:
content.append(line)
# 生成下标
flags = [x * 0 for x in range(len(names))]
# 生成人物联系
for a in range(len(names)):
flags[a] = 1
name_1 = names[a]
for b in range(len(names)):
if flags[b] == 0:
name_2 = names[b]
# 为三个字符时,取名字
if len(name_1) == 3:
name_1 = name_1[1:]
if len(name_2) == 3:
name_2 = name_2[1:]
# 遍历章节及段落
num1, num2 = 0, 0
for i in os.listdir('F:\\Python\\Ordinary_world_1'):
worldFile = open('F:\\Python\\Ordinary_world_1\\' + i)
worldContent = worldFile.read()
if (name_1 in worldContent) and (name_2 in worldContent):
num1 += 1
else:
continue
for j in content:
if (name_1 in j) and (name_2 in j):
num2 += 1
else:
continue
print(names[a], names[b], num1, num2)
# 写入文件中
with open('weight.csv', 'a+') as f:
f.write(names[a] + ',' + names[b] + ',' + str(num1) + ',' + str(num2) + '\n')
f.close()
最后成功获取两两人物间的联系。
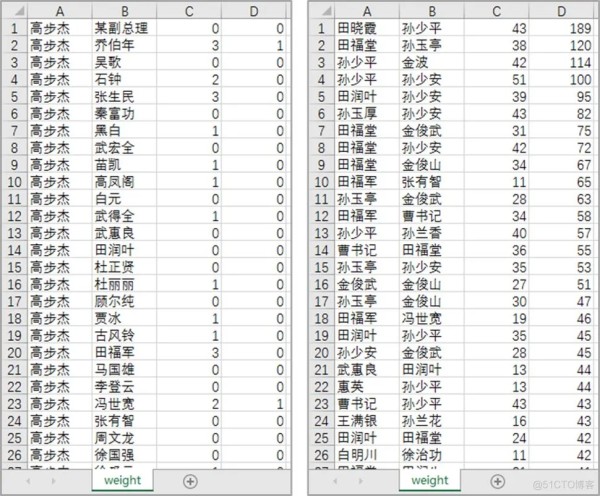
左图为无排序的结果,右图为排序后的结果。
/ 02 / 社交网络
使用获取的数据包,通过networkx生成社交网络图。
详细代码如下。
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
# 显示中文,及字体设置
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['font.size'] = 10
plt.rcParams['axes.unicode_minus'] = False
# 读取文件
df = pd.read_csv('weight.csv', header=None, names=['First', 'Second', 'chapweight', 'duanweight'], encoding='gbk')
print(df.head())
# 计算段落人物关系权重
df['weight'] = df.chapweight / 162
# 获取联系大于4的数据,重新生成索引
df2 = df[df.weight > 0.025].reset_index(drop=True)
plt.figure(figsize=(12, 12))
# 生成社交网络图
G = nx.Graph()
# 添加边
for ii in df2.index:
G.add_edge(df2.First[ii], df2.Second[ii], weight=df2.weight[ii])
# 定义3种边,大于32,16-32,小于16
elarge = [(u, v) for (u, v, d) in G.edges(data=True) if (d['weight'] > 0.2)]
emidle = [(u, v) for (u, v, d) in G.edges(data=True) if (d['weight'] > 0.1) & (d['weight'] <= 0.2)]
esmall = [(u, v) for (u, v, d) in G.edges(data=True) if (d['weight'] <= 0.1)]
# 图的布局
# 节点在一个圆环上均匀分布
pos = nx.circular_layout(G)
# 点
nx.draw_networkx_nodes(G, pos, alpha=0.6, node_size=350)
# 边
nx.draw_networkx_edges(G, pos, edgelist=elarge, width=2, alpha=0.9, edge_color='g')
nx.draw_networkx_edges(G, pos, edgelist=esmall, width=1, alpha=0.3, edge_color='b', style='dashed')
# 标签
nx.draw_networkx_labels(G, pos, font_size=10)
# 生成结果
plt.axis('off')
plt.title('平凡的世界')
plt.show()
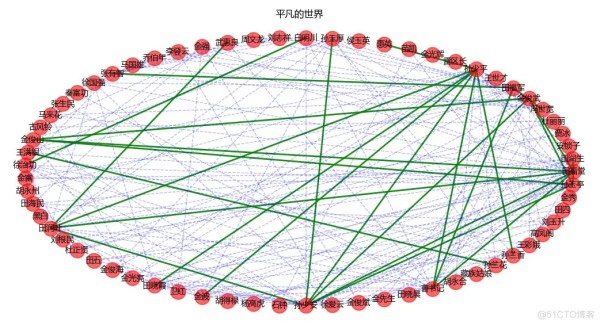
得到的社交网络图。
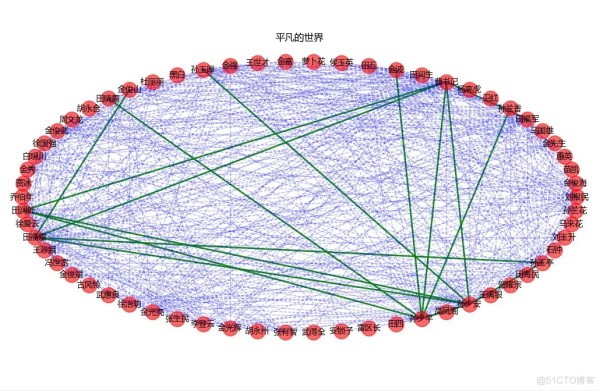
可以看出人物之间的联系交错复杂。
联系较多的则是孙少平、孙少安、田润叶、田福堂以及曹书记。
这里通过网上查看了下《平凡的世界》的简介。
发现少了地主女儿郝红梅这个人物...
算是漏了一个,原本还以为82个人物应该挺全的。
接下来计算一下每个节点(每个人物)的度(入度和出度)。
它在一定程度上反映了该节点的重要程度。
详细的代码如下。
# 计算每个节点的重要程度
Gdegree = nx.degree(G)
Gdegree = dict(Gdegree)
Gdegree = pd.DataFrame({'name': list(Gdegree.keys()), 'degree': list(Gdegree.values())})
# 第一张图,所有人物
#Gdegree.sort_values(by='degree', ascending=False).plot(x='name', y='degree', kind='bar', color=(136/255, 43/255, 48/255), figsize=(12, 6), legend=False)
# 第二张图,前20人物
Gdegree.sort_values(by='degree', ascending=True)[-20:].plot(x='name', y='degree', kind='barh', color=(16/255, 152/255, 168/255), figsize=(12, 6), legend=False)
plt.xticks(size=8)
# 第一张图标签
# plt.ylabel('degree')
# 第二张图标签
plt.ylabel('name')
plt.show()
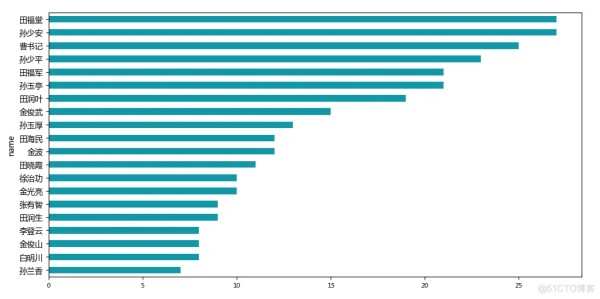
生成节点出、入度直方图。
发现由于信息过多,导致图看得不太清楚。
所以这里选取前20个,进行展示。
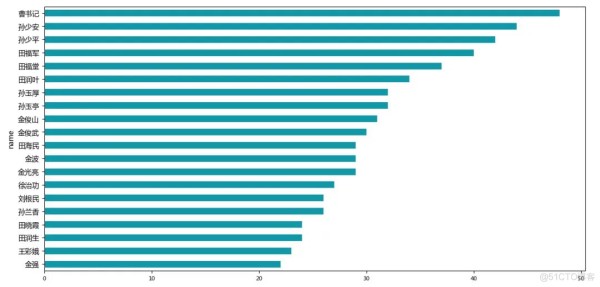
可以看出网络图中重要程度高的是曹书记、孙少安、孙少平等人。
当然上面这些都是以章节为联系的。
换成段落联系应该也会有所改变。
/ 03 / 总结
这应该年前写的最后一篇文章了。
所以在此,预祝大家新年快乐。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【学习】

在公众号后台回复下列关键词可以免费获取相应的学习资料:
Python3、Python基础、Python进阶、网络爬虫 、书籍、
自然语言处理、数据分析、机器学习、数据结构、
大数据、服务器、Spark、Redis、C++、C、
php、mysql、java、Android、其他
赞 收藏 评论 举报相关文章

