StarRocks(性能优化)
优化方案
1、数据模型设计优化 1-1、分区与分桶策略 (高频使用)分区(Partitioning): -- 按时间或业务逻辑字段(如日期、地区)对表进行分区,减少扫描数据量。 CREATE TABLE ads_order ( order_id BIGINT, user_id INT, amount DECIMAL(10,2), dt DATE ) PARTITION BY RANGE(dt) ( PARTITION p202301 VALUES [('2023-01-01'), ('2023-02-01')), PARTITION p202302 VALUES [('2023-02-01'), ('2023-03-01')) ); 分桶(Bucketing): -- 选择高基数字段(如 user_id、order_id)作为分桶键,确保数据均匀分布,避免数据倾斜。 DISTRIBUTED BY HASH(user_id) BUCKETS 32; 1-2、数据冗余与宽表设计 (高频使用)
对高频关联的小表(如维度表),通过 Broadcast Join 或 Colocate Join 避免 Shuffle。 若多表关联逻辑固定,可设计宽表(预关联表),减少运行时 Join 开销。 2、查询优化 (高频使用) 2-1、Join 策略选择
Broadcast Join: -- 适用于小表(如维度表)与大表的关联,将小表广播到所有节点,避免 Shuffle。 SELECT /*+ BROADCAST(dim_user) */ o.order_id, u.user_name, o.amount FROM ads_order o JOIN dim_user u ON o.user_id = u.user_id; Shuffle Join: -- 大表间关联时,按 Join Key 重新分布数据,确保相同 Key 的数据在同一节点。 SELECT /*+ SHUFFLE_JOIN */ o.order_id, p.product_name, o.amount FROM ads_order o JOIN ads_product p ON o.product_id = p.product_id; Colocate Join: -- 若多表的分桶键和分桶数一致,直接本地 Join,无需网络传输。 -- 创建表时指定相同分桶规则 CREATE TABLE ads_order (...) DISTRIBUTED BY HASH(user_id) BUCKETS 32; CREATE TABLE dim_user (...) DISTRIBUTED BY HASH(user_id) BUCKETS 32; -- 查询时自动触发 Colocate Join SELECT o.order_id, u.user_name FROM ads_order o JOIN dim_user u ON o.user_id = u.user_id; 2-2、谓词下推与过滤
-- 在 Join 前尽量过滤数据,减少参与关联的数据量: SELECT o.order_id, u.user_name FROM (SELECT * FROM ads_order WHERE dt = '2023-01-01') o JOIN dim_user u ON o.user_id = u.user_id; 2-3、避免笛卡尔积
-- 确保 Join 条件包含有效关联字段,避免全表扫描。 3、物化视图加速 (高频使用)
-- 对高频复杂查询,通过 物化视图(Materialized View) 预计算关联结果: -- 创建物化视图 CREATE MATERIALIZED VIEW mv_order_user PARTITION BY dt DISTRIBUTED BY HASH(order_id) AS SELECT o.order_id, u.user_name, o.amount, o.dt FROM ads_order o JOIN dim_user u ON o.user_id = u.user_id; -- 查询时自动命中物化视图 SELECT user_name, SUM(amount) FROM mv_order_user WHERE dt = '2023-01-01' GROUP BY user_name; 4、执行计划调优
分析执行计划 使用 EXPLAIN 命令查看查询计划,重点关注: 数据分布:是否触发 Broadcast/Shuffle/Colocate Join。 谓词下推:过滤条件是否提前应用。 资源消耗:是否存在内存溢出(如 EXCEEDED_MEMORY_LIMIT)。 调整并行度 通过 set parallel_fragment_exec_instance_num = 8; 增加并行度,提升计算资源利用率。 调整 BE(Backend)节点的资源配置,避免资源竞争。 5、统计信息收集
定期收集表统计信息,帮助优化器生成高效执行计划: -- 手动收集统计信息 ANALYZE TABLE ads_order COMPUTE STATISTICS; 6、资源隔离与优先级
为 ADS 层查询分配独立资源组(Resource Group),避免与其他任务竞争资源: CREATE RESOURCE GROUP ads_group TO ('user_ads') WITH ( 'cpu_core_limit' = '16', 'mem_limit' = '80%' ); 7、冷热数据分层
对历史冷数据使用 冷存储策略(如对象存储),降低存储成本。 对热数据保留在本地 SSD,提升查询性能。
Explain(逻辑执行计划) 操作案例:
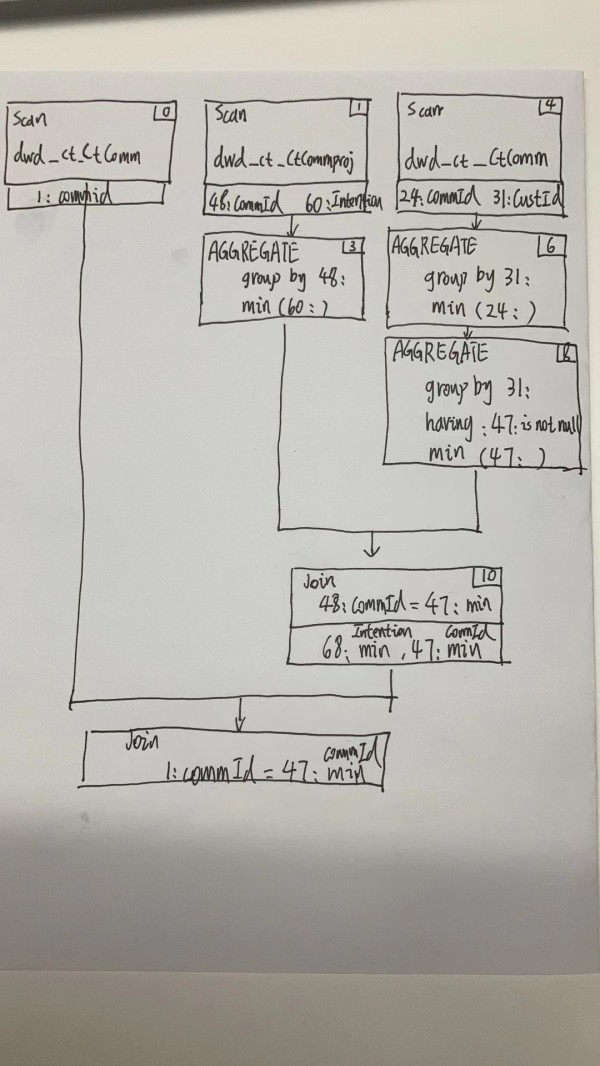
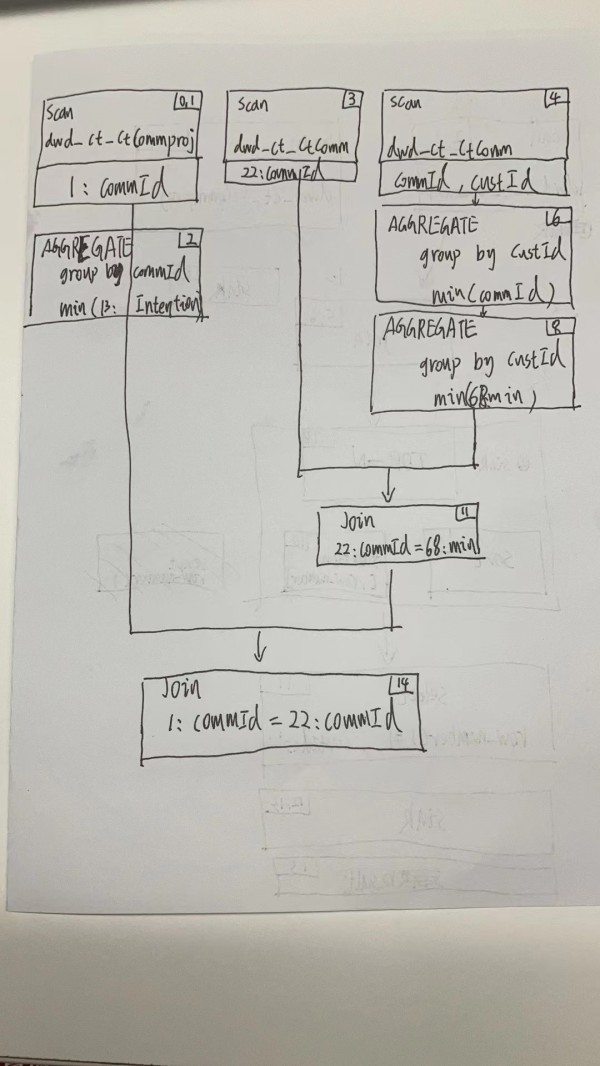
对一下三个语句进行执行计划分析对比,查询优化------------------------------------------ -- EXPLAIN select custId,commOwner,commSchool,commTime,commStatus,commprojIntention from ( select a.custId ,a.commOwner ,a.commSchool ,a.commTime ,a.commStatus, b.commprojIntention, ROW_NUMBER() over(PARTITION by b.custId order by b.commTime) as rnk from datawarehouse.dwd_ct_CtComm a join datawarehouse.dwd_ct_CtCommproj b on a.commId = b.commId and a.commDelstatus = 'N' and a.isPhysicsDel = 2 and b.commprojDelstatus = 'N' and b.isPhysicsDel = 2 ) t where rnk = 1 and custId <> '' ----------------------------------------- -- EXPLAIN select c.custId, c.commOwner, c.commSchool, c.commTime, c.commStatus,a.commprojIntention from ( select commId ,min(commprojIntention) commprojIntention from datawarehouse.dwd_ct_CtCommproj where isPhysicsDel = 2 group by commId ) a join ( select a.commId ,a.custId, a.commOwner, a.commSchool, a.commTime, a.commStatus from datawarehouse.dwd_ct_CtComm a where commId in ( select min(commId) as commId from datawarehouse.dwd_ct_CtComm where commDelstatus = 'N' AND isPhysicsDel = 2 group by custId ) ) c on a.commId =c.commId ----------------------------------------- -- EXPLAIN select a.custId, a.commOwner, a.commSchool, a.commTime, a.commStatus, c.commprojIntention from datawarehouse.dwd_ct_CtComm a join (select min(commId) commId from datawarehouse.dwd_ct_CtComm where commDelstatus = 'N' AND isPhysicsDel = 2 group by custId) b on a.commId =b.commId join (select commId,min(commprojIntention) commprojIntention from datawarehouse.dwd_ct_CtCommproj where isPhysicsDel = 2 group by commId ) c on b.commId =c.commId 执行计划:
----------------------------------------- -- PLAN FRAGMENT 0 OUTPUT EXPRS:8: custId | 7: commOwner | 19: commSchool | 9: commTime | 10: commStatus | 36: commprojIntention PARTITION: UNPARTITIONED RESULT SINK 13:EXCHANGE PLAN FRAGMENT 1 -- 任务碎片 OUTPUT EXPRS: -- 输出表达式 PARTITION: HASH_PARTITIONED: 33: custId -- 分区 STREAM DATA SINK EXCHANGE ID: 13 UNPARTITIONED -- 未分区 12:Project | <slot 7> : 7: commOwner | <slot 8> : 8: custId | <slot 9> : 9: commTime | <slot 10> : 10: commStatus | <slot 19> : 19: commSchool | <slot 36> : 36: commprojIntention | 11:SELECT | predicates: 44: row_number() = 1, 8: custId != '' | 10:ANALYTIC | functions: [, row_number(), ] | partition by: 33: custId | order by: 31: commTime ASC | window: ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW | 9:SORT | order by: <slot 33> 33: custId ASC, <slot 31> 31: commTime ASC | offset: 0 | 8:EXCHANGE PLAN FRAGMENT 2 OUTPUT EXPRS: PARTITION: RANDOM STREAM DATA SINK EXCHANGE ID: 08 HASH_PARTITIONED: 33: custId 7:PARTITION-TOP-N | partition by: 33: custId | partition limit: 1 | order by: <slot 33> 33: custId ASC, <slot 31> 31: commTime ASC | offset: 0 | 6:Project | <slot 7> : 7: commOwner | <slot 8> : 8: custId | <slot 9> : 9: commTime | <slot 10> : 10: commStatus | <slot 19> : 19: commSchool | <slot 31> : 31: commTime | <slot 33> : 33: custId | <slot 36> : 36: commprojIntention | 5:HASH JOIN | join op: INNER JOIN (BUCKET_SHUFFLE) | colocate: false, reason: | equal join conjunct: 24: commId = 1: commId | |----4:EXCHANGE | 1:Project | <slot 24> : 24: commId | <slot 31> : 31: commTime | <slot 33> : 33: custId | <slot 36> : 36: commprojIntention | 0:OlapScanNode TABLE: dwd_ct_CtCommproj PREAGGREGATION: OFF. Reason: None aggregate function PREDICATES: 38: commprojDelstatus = 'N', 42: isPhysicsDel = 2 partitions=1/1 rollup: dwd_ct_CtCommproj tabletRatio=60/60 tabletList=76203,76207,76211,76215,76219,76223,76227,76231,76235,76239 ... cardinality=150433003 avgRowSize=19.56558 numNodes=0 PLAN FRAGMENT 3 OUTPUT EXPRS: PARTITION: RANDOM STREAM DATA SINK EXCHANGE ID: 04 BUCKET_SHUFFLE_HASH_PARTITIONED: 1: commId 3:Project | <slot 1> : 1: commId | <slot 7> : 7: commOwner | <slot 8> : 8: custId | <slot 9> : 9: commTime | <slot 10> : 10: commStatus | <slot 19> : 19: commSchool | 2:OlapScanNode TABLE: dwd_ct_CtComm -- 表名 PREAGGREGATION: OFF. Reason: Has can not pre-aggregation Join PREDICATES: 18: commDelstatus = 'N', 22: isPhysicsDel = 2 partitions=1/1 rollup: dwd_ct_CtComm tabletRatio=60/60 tabletList=75066,75070,75074,75078,75082,75086,75090,75094,75098,75102 ... cardinality=103274862 -- 扫描表的数据总行数 avgRowSize=28.0 -- 扫描数据行的平均大小 numNodes=0 -- 另外两个省略 分析图如下:

网址:StarRocks(性能优化) https://mxgxt.com/news/view/1904150
相关内容
StarRocks物化视图StarRocks vs传统数仓:一场性能与效率的较量
StarRocks 1.19 新版本特性介绍
StarRocks(性能优化)
StarRocks 2.1 新版本特性介绍
StarRocks 相关面试题
StarRocks 物化视图刷新流程及原理
StarRocks数据流处理
StarRocks资源调度
EMR Serverless StarRocks 版
随便看看
最新实时动态
- 很喜欢看这样的李云霄,是释放是开心 杭州首演很成功!台州、宁波再相约!
- 陪完这一场,工程款也就下来了
- 以为自己没有丑照直到打开男朋友的相册
- 女孩为了流量在什么地方直拍了?
- 线下的意义在见到你的时候 什么都烟消云散了 只有见到你的幸福
- 永远相信韩国财阀的眼光
- 沈达为了国家大义,最终还是辜负了深爱他的小阿悄
- 岁月是把杀猪刀,二十年后再看港圈四帅,谁的变化最让你感慨?
- 长公主“有孕”
- “他们不是吃不饱,而是饿的快”
热点实时动态
- 136194
- 25500
- 20093
- 19781
- 19528
- 19485
- 19220
- 18789
- 18768
- 18742

