跨越速运张杰:基于 StarRocks 提升运单分析时效|爱分析活动

2022 年 12 月底,爱分析举办了“2022爱分析·数据智能网络研讨会”。爱分析邀请跨越速运大数据架构师张杰进行了题为《基于 StarRocks 提升运单分析时效》的主题演讲。
在物流行业,由于内部场景复杂、分析需求不断变化、多种分析引擎并存、数据库性能不足等问题,现有的分析系统愈发难以持续,企业迫切需要新的数据引擎支持不断增长的需求。
跨越速运大数据架构师张杰在会上分享了基于 StarRocks 对运单分析架构进行改造升级,提升分析效率的案例,详细讲述了物流行业做数据分析存在的痛点、运单分析架构的升级与收益、当前仍存在的问题和进一步的尝试。

现将演讲实录整理后分享如下:
我是来自跨越速运的张杰,今天我给大家分享一下我们跨越速运是如何基于开源数据库 StarRocks 来提升我们运单分析时效的。首先简单自我介绍一下,我来自于跨越速运集团,跨越速运是一家主营限时速运服务的大型现代化综合企业。目前我们拥有超过 5 万名员工, 3000 家网点,已经覆盖全国超过 500 个城市。跨越速运是国家 5A 级物流运输企业,也是今年中国零担企业排行榜的第二名。总体而言,我们是一家非常有实力的物流企业。
我今天分享的内容包括三个方面:物流行业做分析存在的痛点、运单分析的架构升级与收益、现存的问题与进一步的尝试。
01
物流行业分析之痛
首先,给大家介绍一下物流行业做运单分析的一些业务背景。在互联网行业,数据服务的大部分对象可能是 C 端用户,但是在我们跨越速运,或者整个物流行业,数据服务大部分面向的是企业内部的用户,服务场景包括公司核心流程中各种与订单相关的环节。公司内部用户跟 C 端用户的区别,在于内部用户有更直接的问题反馈渠道。比如,用户发现数据服务出现异常后,可以直接通过我们内部的群或者是邮件的方式快速地反馈问题,所以用户对数据服务体验的要求会更高。
数据服务面向公司内用户和各种复杂场景
目前来说,公司每天有100 多位BI 开发同学在重度地使用跨越速运的大数据平台,平台目前累计开发的数据服务接口超过1 万个,我们的服务面向的是整个公司 ERP 系统,服务的调用量已经超过了每天 1000 万次,所以用户对数据服务的使用体验要求比较高。我们服务的用户就是全公司上下5 万多名的员工,时延 P99 要求在1 秒以内。
除了 OLAP 分析之外,数据服务还提供了绩效工资查询、运单成本分摊、运单时效跟踪等核心业务流程中的关键数据,因为每一笔运单都需要统计实际收益,所以大量的用户(如司机、操作工)通过我们的接口查询其每天的收入,包括每一笔运单的成本折算、每一笔运单的时效跟踪,这些数据都来源于大数据平台。
在物流行业,最核心的分析场景,一定是围绕运单展开的。而运单分析上游的数据来源于各种 ERP 业务系统,目前我们可能有 30 个这样的系统,上游有各种各样的关系型数据库,甚至一些 NoSQL 数据库。我们会通过一些集成工具,将这些数据汇聚在大数据的平台,并经过一些 ETL 的处理,形成我们数仓运单域的数据。最终再经过一些 BI 工具,或者是我们自建的星河大数据平台,给到我们所有的用户去使用。
随着公司业务快速发展,分析场景越来越复杂
随着公司业务的快速发展,我们的分析场景也会越来越复杂。在早期,用户有固定的需求,按照固定维度或固定条件去查询相关结果时,我们可以做数据的预处理,把数据汇聚的结果放在 MySQL,以便用户直接查到相对应的结果。但如今,用户的需求越来越复杂,他们不再满足于通过固定条件查询,而是要求任意字段、以任意维度聚合条件都可以查询。当用户场景越来越复杂,我们也需要性能更强大的引擎来支撑这些需求。
此外,早期的用户可以接受离线批量地更新数据,比如按天或者是按小时地去更新运单数据。但现在用户要求所有的运单数据要能够实时更新,可能在某笔运单的某个环节发生变化后,用户都要能够实时地查到这些运单变化的数据。
最后,用户对使用体验的要求也在提升。以前在 PC 端进行数据分析,用户可以接受秒级响应。但现在更多是通过手机端或者 PDA 端去提供数据服务,这些数据对时效的要求会更高,现在对所有的接口要求是在亚秒级响应。而且,伴随着数据量持续地增加,现在的单表能够达到上亿行了,这对数据库的性能要求也越来越高了。
使用的查询引擎种类太多
为了解决数据分析的各类问题,我们也一直在尝试去使用各种各样的引擎,为了解决实时的问题,我们早期用了 Impala 和 KUDU 这样的引擎;为了解决宽表查询的性能问题,我们用了 ClickHouse;为了解决明细的点查,我们用了Elasticsearch;还有多表关联的复杂分析,我们用了 Presto。但是使用的查询引擎种类太多带来了相应的弊端,对于 BI 开发用户来说,每做一个数据接口或者报表的时候,他都要去决策应该用哪一种引擎,这需要对多种引擎都有一定的了解,导致开发门槛会较高。另外,对于运维用户来说,他也很难去精通多种技术栈,导致数据库的稳定性难以得到保障。
接口性能差
随着数据量的增长,SQL性能变差,开发同学需要花大量的时间去做优化,运维同学也需要持续关注数据库接口的慢请求问题,所以我们迫切需要一个新的数据分析引擎来解决这些问题。

对于新数据库的需求我们总结了一下,为了提升用户体验,我们需要数据库有极致的查询性能;为了让数据处理更实时,我们需要数据库支持实时写入、更新、删除。当然,还要考虑数据库的易用性,因此标准 SQL 和丰富的函数必不可少。如果能高度兼容 MySQL 的协议则会对用户更加友好。另外,对于大数据集成、资源隔离等一些维护性的功能,我们也有一些要求。
02
架构升级与收益
接下来,我给大家介绍一下我们运单分析架构升级和所带来的收益。
引擎统一
第一,我们对 OLAP场景所使用的引擎进行了收敛。在选型中,我们选取了大量市面上流行的数据库做了统一的比对,最终我们决定使用两种数据库,一是 Elasticsearch,该数据库在明细点查的场景比较流行,尤其在海量数据、指定条件的明细检索和查询上性能表现优秀,而且对于高并发的支持也非常好,在类似公司的明细点查或者是运单子件点查等场景,我们都会用 Elasticsearch 来解决。
但是其他大部分分析类场景,我们最终都是用 StarRocks 去进行兜底的,因为 StarRocks 在分析场景下的性能表现非常优秀。我们实际测下来,市面上的数据库很难有在性能上能与 StarRocks 媲美的。第二,StarRocks 兼容 MySQL 协议,因为我们的用户都习惯了用 MySQL,对语法、函数都比较熟悉,所以使用门槛相对比较低。第三,StarRocks 支持按主键更新,它能够解决在实时分析上的问题。第四,StarRocks 支持多种类型的外表,所以我们有一些跨异构数据源联邦查询的场景可以用这种外表的方式解决。此外,因为本身的只有 Backend 和 Frontend 这两种角色,不依赖外部组件,所以 StarRocks 的部署和维护也是比较简单方便的。最后,StarRocks 跟当前我们在用的多种数据加载工具的集成度比较高,数据导入StarRocks 的性能也是非常好的。
性能提升明显
我们做完引擎统一后,接口性能提升明显。在没有引入 StarRocks 之前,我们整体接口的性能 P99 在 1.5 秒左右,当我们切换到 StarRocks 以后,P99 已经下降到 500-520 毫秒左右,性能提升了接近 3 倍。另外,StarRocks简化了 BI 的开发模式。在早前我们很多时候需要做一些宽表的建设,整体开发效率低下。当使用 StarRocks 以后,多表关联的性能问题都可以被很好地解决。在同步基础表之后,用户可以直接通过 StarRocks 接口进行 BI 开发,整个过程提效了接近 20%。第三,因为 StarRocks 的性能比较好,深受业务线的欢迎,目前已经有接近 20 套生产集群、超过 20 个业务线在用 StarRocks。作为目前最核心的 OLAP 查询引擎,StarRocks目前的日均调用量超过 600 万次。
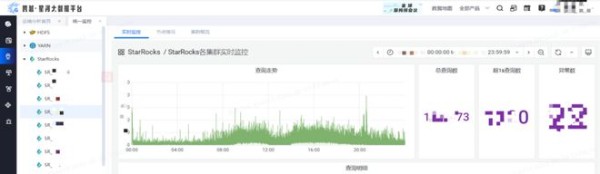
下图是我们基于 StarRocks 自己构建的的管理平台,可以看到其中某一个集群单天的总查询量超过了百万次,超过一秒的查询数是在 1000-2000 次,性能表现是非常好的。
运单分析架构升级
基于StarRocks,我们做的第二件事就是升级运单分析的架构。这张图是我们原有架构的示例,这是典型的离线分析架构,上游数据主要来自于关系数据库。我们将上游的 MySQL 数据同步到 Kafka,这样在 Kafka 里面会根据每一张 MySQL 表生成一个 topic,我们再把这些 topic 数据同步到离线的 Hive 集群中,通过离线的 Presto 或者 Spark 引擎去做运营单宽表的加工处理。
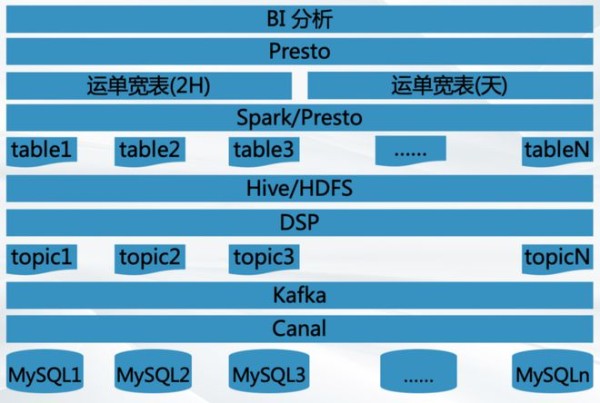
这是传统的处理方式,该架构存在的问题就是数据时效性差,因为采用的是离线处理的逻辑,运算比较慢,数据时效最快只能做到 2 个小时,即每一笔运单变更以后,至少要等上 2 个小时才能看到最新的数据。另外,基于 Presto 做的查询接口性能表现不足,分析的响应时间基本上在 1-10 秒,涉及更复杂的分析时则会更慢,用户体验不好。
为了解决这个问题,我们当时引入了 StarRocks 来提升运单分析的性能。为了提升时效,我们从 Kafka 数据合并这一层引入了 Flink + HBase,利用 HBase 的 CDC 的功能做宽表合并,再反向地把每一行数据完整同步到 Kafka 的 topic 中,这样 Kafka 里面就会有实时的整个运单所有字段完整的数据,再通过 Flink 去实时地写入到 StarRocks 中,最终在 StarRocks 中就有了我们实时运单宽表。基于这张表,我们给用户提供接口或者是 BI 分析。

收益明显
优化后的提升效果也是非常明显的,时效从以前最短 2 个小时缩短到整个链路更新时效小于 5 秒。另外,基于StarRocks,我们运单宽表的分析性能也是大幅提升,现在平均 SQL 运行在 500 毫秒左右,即使特别复杂的 SQL 执行,基本上也能小于 3 秒。
整体而言,该运单分析的架构升级主要基于两点:
一是我们用了 StarRocks 的 Primary Key 模型,该模型相比以前的 Unique Key 模型,性能提升了200%;相比 Presto 引擎,性能提升了 300%。
二是我们用了 Flink StarRocks Connector,它基于 Streamload 微批的方式去更新数据,相比以前的 MySQL JDBC Connector 性能提升了几十倍。所以在做实时数据更新的时候,效率会非常高。另外,结合 Flink 我们能做到运单数据整行地实时更新,整个链路更新的时效能够小于 5 秒。
03
问题与尝试
我们基本上是在今年年初开始使用新的架构。用了一年下来后,其实发现该架构还存在一些问题:
首先,该方案数据链路太长,相比以前的老方案,该架构引入了Flink、Kafka、 HBase 等很多中间环节,尤其数据在 HBase 这一层,可能要来回进出两三次。由于整个链路比较长,所以我们排查问题会非常困难。在碰到有数据丢失的情况下,要逐层地去分析,这个成本是非常高的。
第二,该方案门槛高,很难去复用。我们现在把它用在运单分析上,但其实有一些用户也想尝试把它用在像客户分析这样其他的场景上。但是这个方案要对HBase 的 CDC 功能做一些定制开发,使用的组件比较多、成本比较高,从而导致这个方案很难被复用。
所以我们也在寻找有没有更简单的方案来解决这些问题,其实我们最终期望的架构是:上游数据链路不变,但是我们整个运单宽表的整合和分析能够用一套数据库方案解决。
这里面其实有两种可能:一是基于新型的 HTAP 混合引擎数据库来构建,因为它既有 OLTP 的能力,能够解决数据实时更新的问题,又有一定 OLAP 的能力,能够将数据给到下游去做分析。我们实际上也测了一些 HTAP 的数据库,包括 TiDB、OceanBase 等,他们都是有一定的分析性能。第二个方案是基于 StarRocks,因为我们当时使用的是 StarRocks 较早的版本,它还只能做到整行更新,所以我们才不得已做了这么复杂的方案。但是 StarRocks 新的版本也有尝试开放部分列更新的功能,所以我们新的方案也可以基于 StarRocks 列更新去做尝试,这样的目的是简化整体链路,并且能够保证时效和性能。StarRocks 从 2.3 版本开始,它的 Partial Update 功能其实已经开始公测了,它可以支持通过 Flink Connector 做到部分列的实时更新,我们现在也在测试这个功能。如果这个功能能够真正地被用起来,那么它本身的 OLAP 的性能会是非常好的,能够完全满足我们最终简化运单分析架构的核心诉求。
网址:跨越速运张杰:基于 StarRocks 提升运单分析时效|爱分析活动 https://mxgxt.com/news/view/992495
相关内容
让数据分析极速统一!StarRocks和阿里云一起干了件大事如何利用 StarRocks 加速 Iceberg 数据湖的查询效率
深入命理分析提升婚姻运势的有效步骤
StarRocks 跨集群数据迁移:SDM 帮你一键搞定!
8分钟了解如何做运营活动数据分析
基于明星效应的百草味运营策略分析
StarRocks 相关面试题
StarRocks Summit 2023 技术交流峰会圆满落幕
EMR Serverless StarRocks评测
基于有效点提取的能量分析攻击及置信度分析
随便看看
最新实时动态
- 两个人又开始盯着嘴巴看
- 茅威涛的“突围” 越剧向何处去
- 记者:胖东来的饭真挺好吃,于东来:饭如果不好吃厨师就完蛋了. !
- 刘宇宁谈如何消解内耗
- 现实中谁又不想要一个果郡王这样的对象!
- “你内心的虚伪 导致无辜的女孩离去” 勇敢的心
- 繁星追爱,男友比自己小十岁,成功从情敌手里抢过来
- 绅士礼,好优雅的pretty! 20260718 黄子韬演唱会嘉宾 @王鹤棣_Dylan ·······
- 张艺兴 张彬彬 吴磊 宋威龙 白敬亭 张新成 你最吃谁的颜值~微博VC计划
- 节目里出现尴尬一幕
热点实时动态
- 133759
- 25469
- 20067
- 19756
- 19503
- 19461
- 19193
- 18766
- 18743
- 18716

