使用Bert完成实体之间关系抽取
大创所需,所以写了一个模型用来完成关系抽取。
最后在百度DuIE数据集的完整测试集上达到95.37%正确率
效果:
Source Text: 《在夏天冬眠》是容祖儿演唱的一首歌曲,收录于专辑《独照》中
Entity1: 独照 Entity2: 在夏天冬眠 Predict Relation: 所属专辑 True Relation: 所属专辑
Source Text: 2.花千骨花千骨是由慈文传媒集团制作并发行,高林豹、林玉芬、梁胜权联合执导,霍建华 、赵丽颖领衔主演,蒋欣、杨烁、张丹峰、马可、徐海乔、李纯等主演的古装仙侠玄幻 仙侠剧
Entity1: 赵丽颖 Entity2: 花千骨 Predict Relation: 主演 True Relation: 主演
Source Text: 在与王祖贤恋爱期间的齐秦,也是他事业最辉煌的时期,《大约在冬季》《无情的雨》《不让我的眼泪陪我过夜》《如果云知道》《夜夜夜夜》等经典曲目都是他为王祖贤所创作的,从这些歌也能感受到两个人是真爱,但是为什么就是没有一个结果呢
Entity1: 齐秦 Entity2: 大约在冬季 Predict Relation: 歌手 True Relation: 歌手
Source Text: 《甜蜜与厮杀》是连载在红袖添香网上的一部奇幻魔法小说,作者是kijimi1
Entity1: kijimi1 Entity2: 甜蜜与厮杀 Predict Relation: 作者 True Relation: 作者
使用方法
准备
将DUIE文件路径放置于代码同目录(或者自己的数据,具体可见loader.py),更加具体的获取和数据处理见下文将bert-base-chinese放置于同目录下的bert-base-chinese下或者自行指定位置安装pytorch,cuda,transformer,numpy等组件(实际测试可运行环境为pytorch=1.5.1 transformers=2.5.1)train and eval
(注意,在此之前,请做好数据的获取和预处理,步骤见文)
python3 main.py执行训练,并得到Fine-Tuing后的BERT
python3 demo.py得到样例输出,或自行阅读代码,修改test函数的传入参数内容即可自定义。
如果仅用于测试和实际使用,可以下载已经训练好的Model,然后调用demo.py下对应函数
caculate_acc:计算每一个类别的正确率
demo_output:随机选择样本,输出原文,实体对以及预测的关系,即实例输出
Model download(92.5%正确率的)
地址:https://pan.baidu.com/s/123qVcRa5SBKcMBLWxP5bKQ
提取码:bert
Model download(95.37%正确率的)
链接:https://pan.baidu.com/s/1ffOzN3FZ1foepB6NcSF5qQ 提取码:bert
数据
数据使用的是百度发布的DUIE数据,包含了实体识别和关系抽取
原数据地址:https://ai.baidu.com/broad/download?dataset=dureader
打开后在左侧栏选择knowledge extraction,然后如下界面点击下载train_data.json和dev_data.json,然后放到对应的位置
运行loader.py里的prepare_data,观察到目录里生成了train.json和dev.json
截止这里,数据的预处理完成了,可以运行main和demo
我对数据进行了预处理,提取关系抽取需要的部分
关系设定有49类,还是非常的丰富的
id2rel={0: 'UNK', 1: '主演', 2: '歌手', 3: '简称', 4: '总部地点', 5: '导演',
6: '出生地', 7: '目', 8: '出生日期', 9: '占地面积', 10: '上映时间',
11: '出版社', 12: '作者', 13: '号', 14: '父亲', 15: '毕业院校',
16: '成立日期', 17: '改编自', 18: '主持人', 19: '所属专辑',
20: '连载网站', 21: '作词', 22: '作曲', 23: '创始人', 24: '丈夫',
25: '妻子', 26: '朝代', 27: '民族', 28: '国籍', 29: '身高', 30: '出品公司',
31: '母亲', 32: '编剧', 33: '首都', 34: '面积', 35: '祖籍', 36: '嘉宾',
37: '字', 38: '海拔', 39: '注册资本', 40: '制片人', 41: '董事长', 42: '所在城市',
43: '气候', 44: '人口数量', 45: '邮政编码', 46: '主角', 47: '官方语言', 48: '修业年限'}
数据的格式如下,ent1和ent2是实体,rel是关系

Model
模型就是直接使用Bert用于序列分类的(BertEncoder+Fc+CrossEntropy)
具体的处理就是把ent1,ent2和sentence直接拼接送进模型
相对我之前对Bert的粗糙处理,这里加上了MASK-Attention一起送进模型
Result
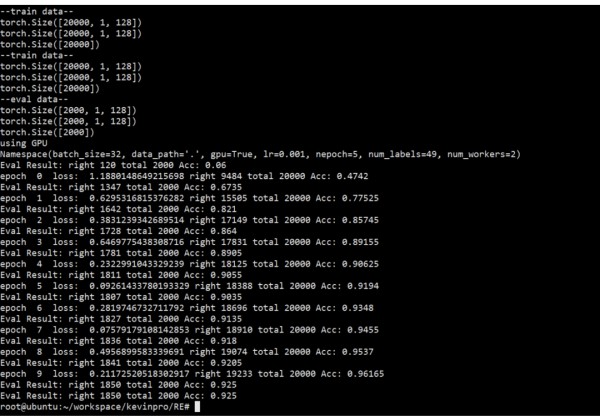
从百度的原数据中选择20000条,测试数据2000条(原数据相对很小的一部分)
训练参数:10 Epoch,0.001学习率,设置label共有49种(包含UNK,代表新关系和不存在关系)
然后在训练前和训练后的分别在测试数据上测试,可以看到Fine-Tuing高度有效
测试集正确率达到 92.5%
修正:后来在所有的数据上训练和测试,测试数据36w,测试数据4w,eval正确率95+%
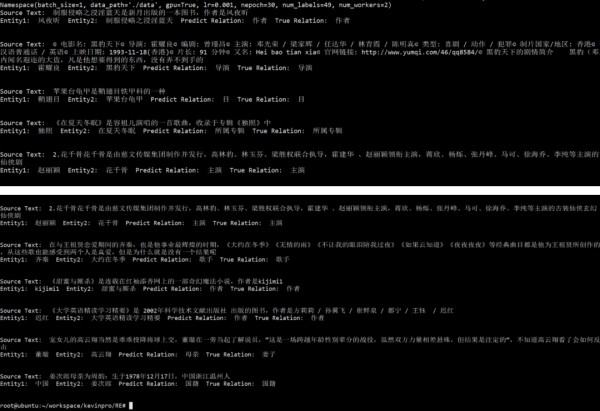
实际测试
在数据中抽取一部分实际测试
效果不错
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-01-20,如有侵权请联系 [email protected] 删除
网址:使用Bert完成实体之间关系抽取 https://mxgxt.com/news/view/2063746
相关内容
大型语言模型在实体关系提取中的革新应用BERT模型全面解析与深度理解
StarUML使用与类之间的关系
使用迪米特法则完成明星与经纪人的关系实例Java实现 什么是迪米特法则
黄子韬掉粉超百万,网友:这是抽完就取关了
如何用数据中台,做一套关于明星的舆情分析系统?
社交媒体数据与语言模型:趋势分析与用户洞察
化妆品使用心得体会
抖音新人券详解(一次性使用、使用条件与领取方法等)
霸王之心手游礼包获取攻略与使用技巧解析
随便看看
最新实时动态
- 王天辰:叔叔年纪年纪大了!怎么说自己是叔叔呢还!
- 侯明昊卢昱晓新剧台词,纪伯宰明意明心曝家庭关系
- 她们把70秒让出去,结果拿下关键席位
- 照顾好自己再奔赴山海!周深寄语:愿每个人自在追逐梦想周深线下人气
- 曹贵人的宫斗手段跟皇后华妃比差点意思,但是在九门里可真是进步了
- 《雀骨》兄长重伤五脏受损,强忍剧痛不肯示弱,只为证明王府不止世子
- 江河说出真相 洛子商原来是他儿子,报复错人了
- 严浩翔被粉丝票价吓到了,快把小严的下巴给合上别着凉了
- Rihanna则以现身价14亿美元,正式成为世界上最富有歌手
- 御廷谣每日12:00会员连更,陈哲远吴谨言主演
热点实时动态
- 145042
- 25600
- 20185
- 19881
- 19614
- 19577
- 19305
- 18885
- 18869
- 18834

