基于Python实现的影视数据智能分析系统
数据分析与可视化是当今数据分析的发展方向,大数据时代,数据资源具有海量特征,数据分析和可视化主要通过Python数据分析来实现,本文给大家介绍了如何基于Python实现的影视数据智能分析系统,文中给出了部分详细代码,感兴趣的朋友跟着小编一起来看看吧

+
目录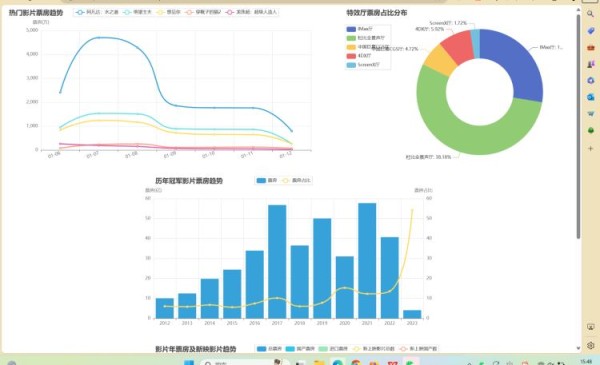
1. 前言
数据分析与可视化是当今数据分析的发展方向,大数据时代,数据资源具有海量特征,数据分析和可视化主要通过Python数据分析来实现。
基于Python的数据分析可视化和技术实现是目前Python数据分析的主要目的,Python可以为数据分析可视化提供思路,在体现数据价值方面发挥着重要作用。因此,在研究数据分析、可视化的过程中,我们可以看到Python具有重要的应用价值。
本文具有影视数据智能分析系统的简单雏形,以不同流媒体电影数据为背景,通过调研、分析数据, 完成数据预处理、数据分析和数据可视化等操作,掌握相关的智能数据处理与智能系统开发的知识,培养智能信息系统项目开发过程中的分析、设计和工程文档编写能力,提高工程应用能力和综合分析、解决实际问题的能力。
2.设计目的及任务描述
影视数据分析应用统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。这一过程也是质量管理体系的支持过程。影视数据分析可帮助人们做出观看影视的选择及投入更合适的影视,尤其对视频管理平台有很好的帮助。影视数据分析是建立在数基础,20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。同时,在数据获取、处理和分析过程中考虑数据安全、技术经济、工程伦理、行业规范等要素。
本设计内容涉及的数据一部分来自Reelgood.com网站,其中包括四种流媒体平台上可用电影的综合列表;另一部分来自IMDB数据集。要求应用pands对下列问题进行数据分析:
你可以在哪个流媒体平台上找到这部电影?在某个国家/地区/IMDB制作的电影的平均IMDb收视率?每个目标年龄段所感兴趣的电影,以及他们所感兴趣的流媒体应用程序。电影的发行年份以及数量。电影和导演的受欢迎程度分析。通过该课程设计的实践训练,使学生掌握相关的智能数据处理与智能系统开发的知识,培养智能信息系统项目开发过程中的分析、设计和工程文档编写能力,提高工程应用能力和综合分析、解决实际问题的能力。
3. 总体设计
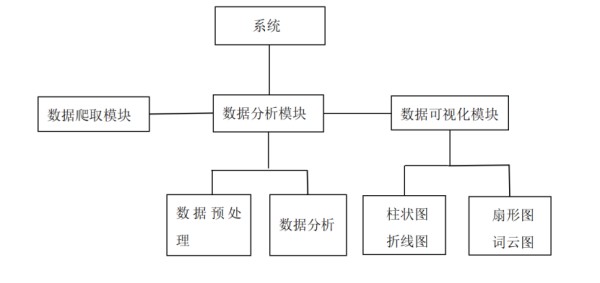
本系统主要分为四个部分,分别为爬虫抓取、数据处理分析可视化、GUI界面展示、启动运行,分别对应getData.py、pyec.py、GUI.py、main.py四个文件。并且包含data文件夹用于存储系统所需或产生的数据文件。
系统结构如图所示:
4.系统实现
4.1 爬虫抓取
getData.py该文件主要功能是抓取和读取电影数据,共包含8个函数,代码如下:
recently() 这一函数主要是抓取最近上映票房排名前十名的电影信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def recently():
url = "https://ys.endata.cn/enlib-api/api/movie/getMovie_BoxOffice_Day_Chart.do"
header = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36',
"Cookie": 'JSESSIONID=b2685bfa-aa4f-4359-ae96-57befaf8d1ec; route=4e39643a15b7003e568cadd862137cf3; Hm_lvt_82932fc4fc199c08b9a83c4c9d02af11=1649834963,1649852471,1649859039,1649900037; Hm_lpvt_82932fc4fc199c08b9a83c4c9d02af11=1649917933'
}
post_BoxOffice_Day_data = {
'r': 0.7572955414768414,
'datetype': 'Day',
'date': datetime.now().strftime('%Y-%m-%d'),
'sdate': datetime.now().strftime('%Y-%m-%d'),
'edate': datetime.now().strftime('%Y-%m-%d'),
'bserviceprice': 1
}
以上代码块是运行爬虫前的准备工作,包含抓取的网址url、爬虫所需的请求头、请求时需要附带的数据。
1
2
3
4
res = requests.post(url, headers=header, data=post_BoxOffice_Day_data).text
json_data = json.loads(res)
data0 = json_data['data']['table0']
data1 = json_data['data']['table1']
以上代码块是运行爬虫并将其解析为json形式,方便后面对数据进行取出。
1
2
3
4
5
6
7
8
9
10
movie_rank = []
movie_details_MovieName = []
movie_details_BoxOffice = []
movie_details_ShowCount = []
movie_details_AudienceCount = []
movie_details_Attendance = []
movie_percent_BoxOfficePercent = []
movie_percent_ShowCountPercent = []
movie_percent_AudienceCountPercent = []
以上代码是部分定义的所需的数据字段。
1
2
3
4
5
6
7
for i in range(10):
movie_rank.append(data0[i]['Irank'])
movie_details_MovieName.append(data0[i]['MovieName'])
movie_details_BoxOffice.append(data0[i]['BoxOffice'])
movie_details_ShowCount.append(data0[i]['ShowCount'])
movie_details_AudienceCount.append(data0[i]['AudienceCount'])
movie_details_Attendance.append(data0[i]['Attendance'])
以上是从json数据中取数据的过程。
showing() 这一函数主要抓取最近正在上映的所有电影的基本信息。
history() 这一函数主要是读取历史电影数据并返回列表格式
1
2
3
4
def history():
data = pd.read_csv("data/moviesBoxOffice.csv", encoding='gbk')
data = np.array(data[:100]).tolist()
return data
利用pandas库读取csv文件,numpy对DataFrame形式数据转换为list格式的过程。
predict_data() 这一函数主要是读取历史电影数据进行建模,建模完成后,读取需要预测的在映电影数据,对其进行票房预测并返回。
hotMovies() 这一函数主要是抓取当前在映票房前五的电影七天内的票房数据。
special() 这一函数主要抓取的是当前电影市场特效影厅种类及其票房占比的数据。
champion_year() 这一函数主要抓取的是近十年来中国电影市场每年票房冠军影片的票房数据,还抓取了近十年国内电影市场的票房和上映影片数量等相关数据。
Tablets() 这一函数主要是对近期在映电影的排片数据进行抓取并返回。
4.2 GUI界面运行
GUI.py该文件主要是为系统构建GUI界面,共有15个函数,具体代码如下:
create_tree_showing该函数主要是为正在上映的电影数据创建数据表格。代码块先是确定数据表头,然后创建表格并设置其父窗体,表格一次性显示数据行数,是否显示表头等参数,然后分别设置表格数据列及每列的宽度。代码块设置表头文本信息,再设置该信息表的垂直滚动条。
create_tree_tablets该函数主要是为在映电影的排片数据创建数据表格。
create_tree_history该函数主要是为历史电影数据创建数据表格。
create_tree_predict该函数主要是为在映电影票房预测结果数据创建数据表格。
clear_tree该函数主要功能是在切换展示数据表格时,对已展示表格数据进行清除。
该函数有一个tree参数,首先对tree进行销毁,再对该表格的垂直滚动条进行销毁。
showing该函数对应按钮’在映电影’,用于实现获取在映电影数据功能。
history该函数对应按钮’历史电影’,用于实现获取历史电影数据功能。
predict该函数对应按钮’在映电影票房预测’,用于实现对在映电影票房预测并展示。
tablets该函数对应按钮’拍片分析’,用于实现获取排片分析数据功能。
center_window该函数是创建整个GUI窗体的函数。
clicking该函数对应’在映电影分析’按钮,用于跳转在映电影分析网页。先调用getData.py下的recently函数获取在映电影数据,再调用pyec.py文件下的Showing函数进行统计图表制作,最后跳转到数据图表网页。
clicked该函数对应’历史数据分析’按钮,用于跳转电影票房分析网页。
industry该函数对应’数据大盘’按钮,用于跳转数据大盘网页。
ui_process该函数主要是对GUI窗体控件等进行布局。创建根窗体,设置GUI的名称,大小,整体高亮颜色,对内部子窗体进行了初始化并且在子窗体的左上角添加了一张logo图片。在子窗体设置了各个功能对应的按钮。设置了整体窗体的布局,以及各个子窗体控件的设置,设置了窗体列参数及运行了整个窗体。
4.3 启动运行
main.py该函数是整个系统的GUI入口,调用并运行了GUI。
1
2
3
4
5
from GUI import uiob
if __name__ == '__main__':
ui = uiob()
ui.ui_process()
5.可视化设计
pyec.py该文件主要是对getData.py文件获取到的数据进行可视化操作,共有3个函数,代码功能详解如下:
History()该函数主要是对历史电影数据进行可视化,具体代码如下:
1
2
3
4
5
csv_file = 'data/moviesBoxOffice.csv'
data = pd.read_csv(csv_file, encoding='gbk')
data_type = data['影片主分类'].value_counts()
data_BoxOffice = data['总票房(万)'][:10]
该代码块主要是读取历史电影票房数据为画图做前期准备工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
a = (
Bar(init_opts=opts.InitOpts(height="450px", width="900px", theme=ThemeType.MACARONS, bg_color='white'))
.add_xaxis(list(data_type.index))
.add_yaxis("类型", list(data_type))
.set_global_opts(
title_opts=opts.TitleOpts(title="票房TOP1000类型统计"),
)
)
b = (
Bar(init_opts=opts.InitOpts(height="450px", width="900px", theme=ThemeType.LIGHT))
.add_xaxis(list(data['影片名称'][:10]))
.add_yaxis("票房", list(data_BoxOffice))
.set_global_opts(
title_opts=opts.TitleOpts(title="票房TOP10总票房统计"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 20})
)
)
c = (
Line(init_opts=opts.InitOpts(height="450px", width="900px", theme=ThemeType.LIGHT))
.add_xaxis(list(data['影片名称'][:10]))
.add_yaxis("总票房(万)", list(data['总票房(万)'][:10]), is_smooth=True)
.add_yaxis("首日票房(万)", list(data['首日票房(万)'][:10]), is_smooth=True)
.add_yaxis("首周票房(万)", list(data['首周票房(万)'][:10]), is_smooth=True)
.add_yaxis("首周末票房(万)", list(data['首周末票房(万)'][:10]), is_smooth=True)
.add_yaxis("点映票房(万)", list(data['点映票房(万)'][:10]), is_smooth=True)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True),
linestyle_opts=opts.LineStyleOpts(width=3))
.set_global_opts(
title_opts=opts.TitleOpts(title="票房TOP10各类票房统计", pos_left='top'),
xaxis_opts=opts.AxisOpts(name="影片名称", axislabel_opts={"rotate": 20}),
yaxis_opts=opts.AxisOpts(name="票房(万)")
)
)
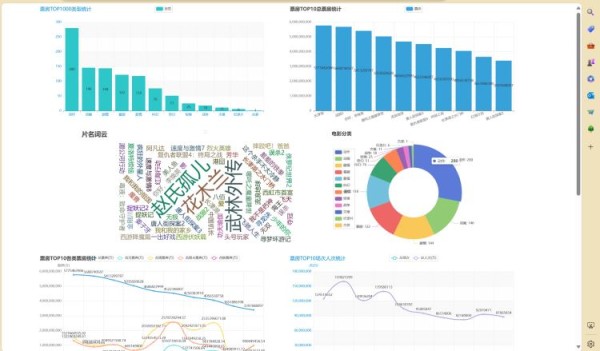
以上代码主要是针对各种数据指标进行数据可视化,最后将其显示到网页供程序调用。两个柱形图分别对票房Top1000的电影类型和票房Top10的总票房进行统计。五个折线图分别是对票房Top10电影的各类票房、场次人次、票价、舆情、口碑五个方面的统计。最后两个图为电影名称词云图和电影分类饼图。
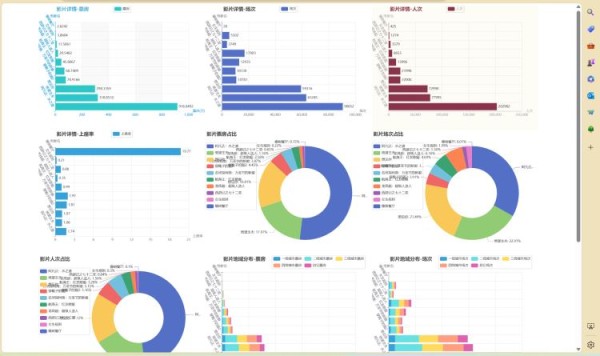
Showing()该函数主要是对正在上映的电影进行数据分析,包含在映电影的票房、场次、人次、上座率五个柱形统计图,影片票房占比、场次占比、人次占比三个饼状统计图,影片地域分布票房、场次、人次三个层叠柱形图。
Industry()该函数主要是对近期电影行业及电影行业历史数据的可视化,主要包括热门电影票房趋势折线统计图,特效厅票房占比分布饼状图。
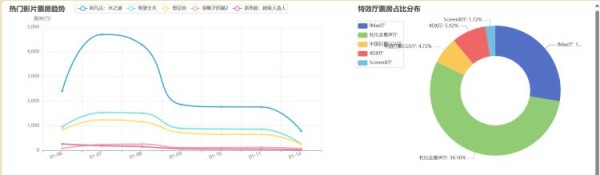
6.总结
通过该课程设计的实践训练,使学生掌握相关的智能数据处理与智能系统开发的知识,培养智能信息系统项目开发过程中的分析、设计和工程文档编写能力,提高工程应用能力和综合分析、解决实际问题的能力。
下面是该系统的主要功能及技术指标:
数据获取和预处理:
使用pandas读取数据文件;拆分不同的属性信息,形成列表、元组、字典或集合;删除空列或行;观察数据并清洗错误数据;
-使用pandas对数据整理,方便之后的分析和可视化。
数据分析:
使用numpy和pandas对数据预处理后的数据进行分析,设计七种以上的数据分析场景。
数据可视化:
利用Matplotlib和seaborn分别对每种分析场景可视化。
数据涉及的数据项:-ID -Title -Year -Age -IMDb -Rotten Tomatoes -Netflix -Hulu -Prime Video -Disney+ -Type -Directors -Genres -Country -Language -Runtime
使用到的库包括:numpy、pandas、matplotlib、seaborn等。开发工具选用jupyter notebook或python IDE等Python开发工具。
以上就是基于Python实现的影视数据智能分析系统的详细内容,更多关于Python影视数据分析系统的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:
Python中的数据分析详解基于Python的数据分析与可视化Python爬虫获取全网招聘数据实现可视化分析示例详解Python+pandas数据分析实践总结Python中Pandas库的数据处理与分析网址:基于Python实现的影视数据智能分析系统 https://mxgxt.com/news/view/2062196
相关内容
基于Python实现的影视数据智能分析系统基于python的NBA球员数据可视化分析的设计与实现.docx
基于Python的直播数据采集与分析
基于Python语言的微博网络数据可视化系统设计与应用
python电影数据分析
计算机大数据毕业设计推荐:基于大数据的音乐人社交媒体粉丝数据的可视化分析系统【python+Hadoop+spark】【前后端全栈、数据分析、python毕设项
基于大数据的电影数据爬取分析可视化系统
基于大数据的多维数据分析系统设计与实现
Python编程实现Taylor Swift粉丝数据分析与可视化工具
数据的舞台:Python 数据可视化的聚光灯
随便看看
最新实时动态
- 泫雅 欢乐吃瓜课 微博VC计划微博VC计划
- 周也在《地球超新鲜》里自曝不吃一切带瓜味的东西!
- 明兰为闺蜜打马球被盛宏责罚,小公爷发誓要娶明兰
- 谢苗打戏拳拳到肉,每一招都够狠够硬够痛快,太炸裂了
- 柳柳周佑凌路灯约会和好,如今直接见家长
- 安陵容做太后了!这张脸来演权倾朝野的太后很有信服力
- 乱世见人品,体面不是人人都有!
- 雅克·德米导演合集
- 文化人取名字就是好听
- 《三十而已》王漫妮200元善意保住柜姐工作
热点实时动态
- 122154
- 25449
- 20048
- 19732
- 19489
- 19444
- 19179
- 18751
- 18718
- 18699

