“社会科学中的数据可视化”第410篇推送
LaTeX是当下应用范围最广的排版软件之一,无论是书籍出版还是论文发表,LaTeX都可以给生成一份排版优雅的文章。而同时,R语言也是学界使用最广泛的统计计算和数据挖掘软件之一。本次推送将给出一种将两者结合在一起的解决方案,利用stargazer包直接将R语言得到的统计或回归结果输出为LaTeX格式。
安装软件包并加载 install.packages( "stargazer")library(stargazer)
如果安装失败或下载速度太慢,建议更换国内镜像,以清华大学CRAN镜像为例:
options(repos=structure(c(CRAN= "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))) 原始数据表格输出
以R语言自带的数据集attitude为例,我们将表格的前5行数据输出:
attitude[ 1: 5,] #R语言自带的输出stargazer(attitude[ 1: 5,], summary=FALSE, rownames=FALSE) #利用stargazer输出
R语言自带的输出结果如下:
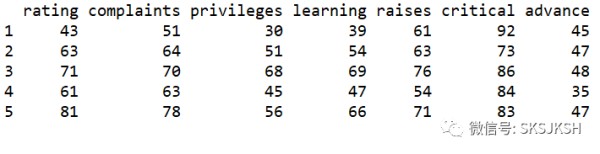
结果看似整齐,但直接复制到Word中,制表符会乱掉,必须手动重新调整。而这种输出更是无法变为LaTeX格式,只能手动输入,效率极低。
我们再来看stargazer的输出:
% Table created by stargazer v .5.2by Marek Hlavac, Harvard University. E-mail: hlavac at fas.harvard.edu% Dateand time: 周六, 12月 23, 2017- 22: 03: 13
begin{table}[!htbp] centering caption{} label{} begin{tabular}{@{extracolsep{ 5pt}} ccccccc} [- 1.8ex]hline hline [- 1.8ex] rating & complaints & privileges & learning & raises & critical & advance hline [- 1.8ex] $ 43$ & $ 51$ & $ 30$ & $ 39$ & $ 61$ & $ 92$ & $ 45$ $ 63$ & $ 64$ & $ 51$ & $ 54$ & $ 63$ & $ 73$ & $ 47$ $ 71$ & $ 70$ & $ 68$ & $ 69$ & $ 76$ & $ 86$ & $ 48$ $ 61$ & $ 63$ & $ 45$ & $ 47$ & $ 54$ & $ 84$ & $ 35$ $ 81$ & $ 78$ & $ 56$ & $ 66$ & $ 71$ & $ 83$ & $ 47$ hline [- 1.8ex] end{tabular} end{table}
将代码复制到LaTeX中,排版后的结果比上面的好了很多:
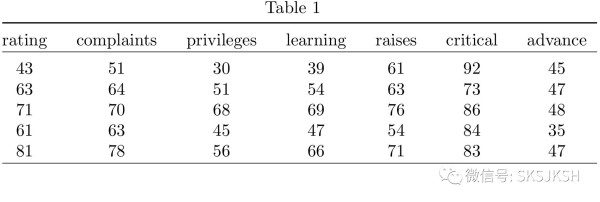
为了节省篇幅,下面我们略去所有的R语言自带的输出结果和stargazer包输出的LaTeX代码,仅显示排版后的最终效果。
描述性统计输出
下面展示如何将初步的描述性统计表述输出成LaTeX格式。
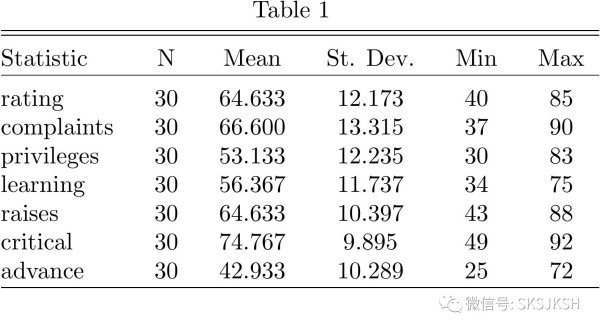
data( "attitude") #读入数据集summary(attitude) #输出R语言自带的描述性统计结果stargazer(attitude) #使用stargazer生成LaTeX语言下的描述性统计表格
将stargazer输出的代码复制到LaTeX中,排版后的结果如下
回归结果输出
下面所有的回归可能不代表任何实际的经济学含义,我们仅仅为了展示stargazer包的作用和操作流程演示了这几个回归。
首先,我们把评分 (rating) 作为因变量,其余6个变量都当成是解释变量,进行线性回归:
linear .1<- lm(rating ~ complaints + privileges + learning + raises + critical, data=attitude)
我们再做一个OLS,被解释变量仍为评分,自变量换为complaints, privileges和learning:
linear .2<- lm(rating ~ complaints + privileges + learning, data=attitude)
最后,我们把评分大于70的认为是好评 (1),剩余的认作差评 (0),构成一个指示变量 (indicator variable),用probit模型进行回归:
attitude$high.rating <- (attitude$rating > 70) #新生成一列上面提到的 0- 1指示变量probit.model <- glm(high.rating ~ learning + critical + advance, data=attitude, family = binomial(link = "probit")) #用probit模型进行回归stargazer(linear .1, linear .2, probit.model, title= "Results", align=TRUE) #输出上述 3个回归的表格
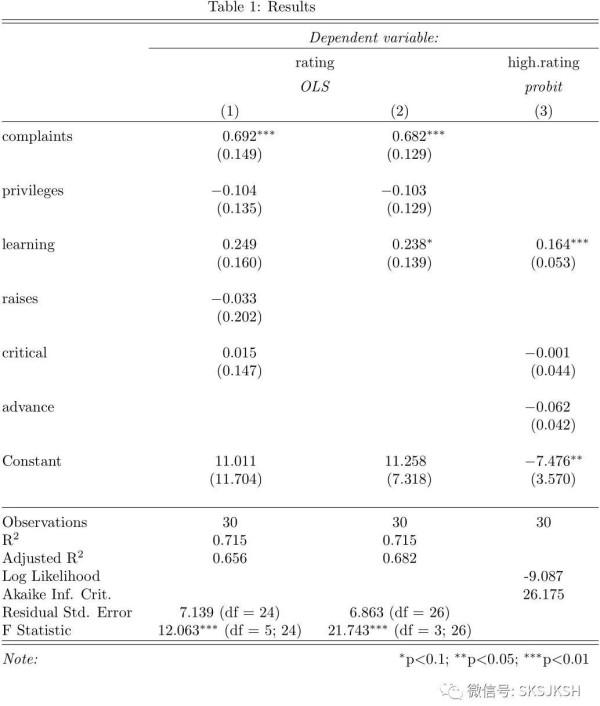
格式微调
在上面回归的表格中,有些行的部分单元格为空,比如Log Likelihood,影响美观。我们或许可以在别的地方报告这个值,或者直接略去这一行。即便撇开美观因素,在输出时,很多时候并非整个表格需要被展示,可能只是一部分的行和列需要呈现在最终的文章之中。
另外,上面的表格把原始数据的名称直接输出成表格最左边的一列,我们通常需要对这些变量重新命名,增加可读性。
针对这两个问题,我们可以利用如下代码进行调整:
> stargazer(linear .1, linear .2, probit.model, #输出两个OLS和一个probit回归结果+ title= "Regression Results", #表格标题为Regression Results+ align=TRUE, #对齐+ dep.var.labels=c( "Overall Rating", "High Rating"), #命名两种回归所对应的被解释变量+ covariate.labels=c( "Handling of Complaints", "No Special Privileges", #命名解释变量+ "Opportunity to Learn", "Performance-Based Raises",+ "Too Critical", "Advancement"),+ omit.stat=c( "LL", "ser", "f"), #略去对数似然、标准化残差和F值这三行+ no.space=TRUE) #删除表格中的空行,使表格更加紧凑
最终的结果如下图:
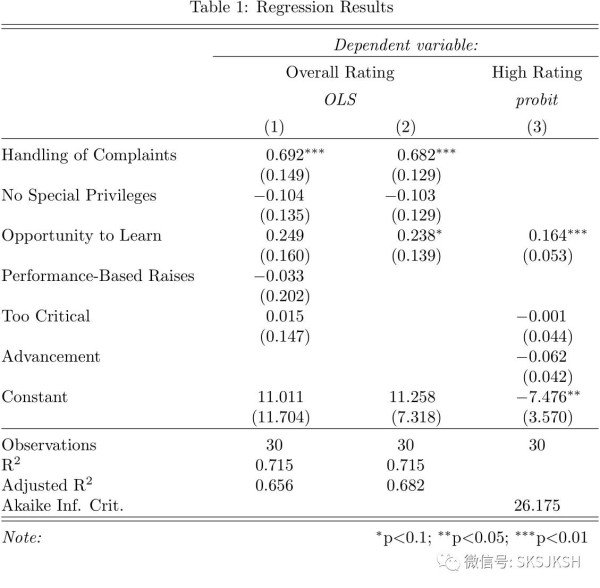
注:操作平台为R Studio (R 3.4.2)
文章来源:Hlavac, Marek (2015). stargazer: Well-Formatted Regression and Summary Statistics Tables. R package version 5.2.,有删改。原文点击“阅读原文”
广受欢迎的微信公共账号“社会科学中的数据可视化”每周推送ArcGIS、Python、R、Stata等软件在社会科学各领域中的运用实例及教程。本帐号由复旦大学经济学院陈硕教授及其团队负责。欢迎媒体及学界与我们展开内容合作,联系邮箱[email protected]。查看以前推送:点“社会科学中的数据可视化”并选择“查看历史消息”。搜寻帐号: SKSJKSH)或扫描二维码如下:返回搜狐,查看更多

