Weights&Biases,支持AI明星公司训练模型的幕后英雄

有一家公司,OpenAI、Anthropic、Cohere、Aleph Alpha(欧洲顶尖大模型公司)和Hugging Face的模型训练和微调都离不开它,NVIDIA和谷歌云(GCP)都是它的深度合作伙伴,它是支持生成式AI明星公司们训练模型的幕后英雄。
这家公司是Weights&Biases,最近获得前GitHub首席执行官Nat Friedman和前YC合伙人Daniel Gross共同投资的5000万美元战略投资,它的现有投资者们Coatue、Insight Partners、Felicis、Bond、Bloomberg Beta和Sapphire也参与了这一轮投资。
此前,它获得Insight Partners领投的4500万美元B轮融资和Felicis领投的1.35亿美元C轮融资,目前累计融资2.5亿美元,是估值12.5亿美元的独角兽。
它打造了一个MLops(机器学习运营)平台,主要用户群体是AI开发者。AI开发者们可以在这个平台上训练和微调AI模型,并能很好地管理AI模型的版本,还能以最优的方式管理训练算力。基于这些功能,可以说只要是AI领域的公司和研究组织,都离不开这个平台。
OpenAI也是Weights&Biases的使用者,ChatGPT和GPT-4都是在它的MLops平台上训练和微调的。
AI领域连续创业者瞄准了模型训练的痛点Lukas Biewald和Chris Van Pelt共同创立了Weights&Biases,他们本身就在机器学习工程师和数据科学家所用的工具方面有多年积累,之前也一起创立了Figure Eight(2019年被Appen以1.75亿美元收购),Figure Eight的主要业务是招募众包工作者为机器学习算法标记模型训练数据。

在这次创业过程中,他们发现了更广泛和强烈的需求:机器学习开发者们没有一个能很好的记录他们模型训练实验的系统。这些至关重要的AI试验被记录在电子表格和低质量的截图中,管理困难。
面对这个痛点,Lukas Biewald和Chris Van Pelt以及Weights&Biases的第三位联合创始人Shawn Lewis(前Google员工)试图共同解决这个问题。
经过几年的探索,Weights&Biases创建了MVP:支持机器学习开发生命周期的工作流程平台。
经过几年迭代后,Weights&Biases打造了完善的MLOps平台,它可以迅速跟踪AI实验、版本化并迭代数据集、评估AI模型性能、复制AI模型、可视化监控模型,并与让开发者与自己和其他团队的同事分享研究成果和观点。这使得机器学习工程师能够迅速迭代他们的机器学习流程。
随着对AI的需求增长,开发者们对MLOps平台的需求也在增长。根据Allied Market Research的研究,2023年MLOps细分市场的价值达到200亿美元左右。
Lukas Biewald用一个例子点出了Weights&Biases能够解决的问题:“如果你有一个控制自动驾驶汽车的AI模型,而汽车发生了事故,你必须知道发生了什么。如果你几年前训练了这个AI模型的初始版本,从那时起到现在进行的所有AI训练和试验,除非你有完善的记录和跟踪,否则你很难系统地追踪发生了什么,并找到问题所在。”
Weights&Biases的增长副总裁Lavanya Shukla也透露了公司与OpenAI的合作细节:“OpenAI在我们的平台上训练所有模型。有数百名员工运行数千个AI试验和训练,对于OpenAI,能够快速测试、识别问题并快速调试他们的模型是至关重要的。得益于Weights&Biases的平台,他们能够更快地训练GPT-4。”
Weights&Biases的B轮领投方Insight Partners表示:“我们从未见过一个像Weights&Biases这样拥有如此高的NPS(净推荐值,可以显示口碑的好坏)和深度客户关注的MLOps类别领导者。它在过去两年增长了60倍。”
Weights&Biases让训练AI模型的“炼丹师”们开了“天眼”Weights&Biases主要面对的是AI开发者群体,就像Github面对的是程序员,它解决的也是AI开发者面对的共性问题。
这些问题包括:
训练AI模型时要做多次试验,如果模型训练完后出现了错误,是哪一次试验的问题?训练模型的数据集,怎么管理和优化,怎么知道哪些数据对训练模型的效果最优?
在有限的算力资源下,怎么将算力进行最优的分配?
在训练模型时,哪些特征和超参数是最有用的?
在团队协作时,怎么与团队里的其他成员分享试验结果?
甚至,在模型训练好后,还可以对模型进行监控,并且可以简单的利用模型搭建AI应用。总之,它能够端到端管理机器学习工作流程。
Weights&Biases功能完善的MLOps平台Weights&Biases的MLOps平台分为三大部分,分别是W&B Models,W&B Prompts和W&B Core。
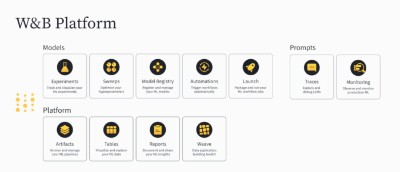
W&B Models主要对模型训练阶段进行管理,具有包括实验追踪、模型管理、ML工作流程规模化和超参数优化等功能。
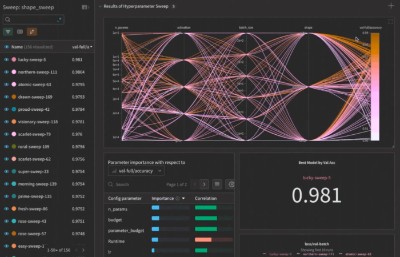
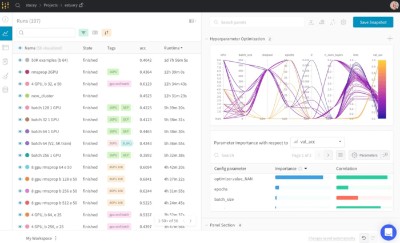
例如W&B Models的Experiment-tracking可以为AI模型训练留下记录,Model-Registry能对AI模型进行生命周期管理,Launch能管理算力分配,并提升对模型训练的可观察性,Sweeps能让AI开发者了解哪些超参数具体起了什么作用。
W&B Prompts帮助AI开发者们深入了解、监控和诊断大语言模型,并能用来搭建基于AI模型的应用。
例如Traces可以帮助AI开发者轻松回顾过去的模型试验结果,识别并调试错误,还能让开发者深入了解AI模型内部的结构。
LLM Monitoring可以帮助AI开发者评估模型的性能,还能用它搭建基于大模型的简单应用,包括问答式聊天机器人,结构化数据抽取工具,客户关系管理工具等。
W&B Core则包含大语言模型的数据管理,可视化和团队写作功能。
例如Artifacts可以随着时间的推移跟踪数据集和模型的演变,Tables可以快速查询和操作训练用数据集中的数据,Reports则让AI开发者无缝分享图形、笔记和实验,并且让同一个团队的成员评论和编辑机器学习项目,提高开发效率和团队协作紧密度。
Aleph Alpha的技术副总裁Samuel Weinbach分享了Weights&Biases的MLOps平台在他们团队中的实际应用,可以更直观地理解这一平台在具体场景中起的作用。
首先,Weights&Biases平台的交互式可视化用户界面使Aleph Alpha团队能够全面了解他们的端到端大型语言模型,这让他们能够快速迭代假设,并实时查看哪些超参数和模型架构表现最好,然后迅速决定接下来要往哪个方向进行试验。Weights&Biases的仪表板以直观的图表和图表呈现这些数据,使其更容易发现趋势、异常或改进的机会。
其次,对整个系统硬件利用的可视化,能够让团队解决这样的问题:是否使用了太多的GPU资源,训练瓶颈在哪里,什么是最佳的批量大小?
由于大语言模型的训练是一项资源密集型的工作,这确保了Aleph Alpha能够有效地最大化其计算基础设施。
最后,Weights&Biases平台让Aleph Alpha的团队可以分享AI训练试验的结果、团队成员反馈,并拥有一个所有项目知识都集中的地方。这让团队实现了无缝的沟通,激发了创意。
迄今为止, Aleph Alpha利用Weights&Biases平台进行了62000次模型训练试验,总计271000小时,其中最长的训练运行为960小时。
从开发者入手“俘获”顶尖企业客户OpenAI、DeepMind、MetaAI、Midjourney、StabilityAI、NVIDIA、Microsoft、Anthropic、Cohere和Hugging Face、Aleph Alpha等公司均为Weights&Biases的客户,可以说大多数处于生成式AI浪潮之上的明星公司,都在用它。
而且,它的客户群是由下而上的,它有超过70000名个人用户,分布在200多家AI公司。
在生态建设上,Weights&Biases也与NVIDIA AI和谷歌云(GCP)进行了合作,采用NVIDIA AI Enterprise的组织能够利用Weights&Biases的MLOps平台加速计算机视觉、自然语言处理和生成AI的深度学习工作负载。
谷歌云的客户也可以在Weights&Biases中跟踪所有的实验和结果,并访问完整的模型和数据溯源。
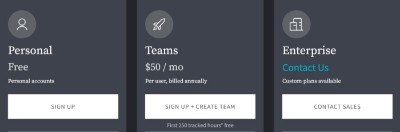
在定价策略上,Weights&Biases对于个人开发者是免费的,对于10人以下的小团队定价50美元,对于企业用户,则按照团队规模定制化定价。并且,它针对小团队的定价已经进行了数次的下调。这种定价方式对于个人用户和小团队是非常友好的,也由此受到了开发者群里的广泛欢迎。
而且AI的探索和开发,对于团队规模并没有高要求(Midjourney的小规模团队获得了上亿美金收入),所以先搞定小团队,然后当这个团队扩大时再升级成企业用户。事实上,Weights&Biases的ARR已经是数千万美元量级,年同比增长150%,NDR(收入留存)的增速也超过150%,这个策略获得了回报。
MLOps领域的机会在创业公司几年前,人们把训练AI模型说成“炼丹” ,暗喻AI模型训练的不透明性和不可控性,而Weights&Biases这样的MLops平台则让“炼丹师”们开了“天眼”。而且Weights&Biases的市场还不仅在于模型的训练,更在于微调。
毕竟基础模型的数量是有限的,但是只要还想在AI领域有所作为,不管用的是自己的模型,还是别人的模型,微调都是绕不开的。微调的需求相比模型训练的需求,大了很多倍。
显然,对于这种需求,不仅Weights&Biases看到了,还有不少其他创业团队有看到了。针对AI模型的试验管理,有Comet和Neptune与它竞争,模型监控则有ArizeAI,FiddlerAI和WhyLab等。
此外,Seldon、FedML、Qwak、Galileo、Striveworks等公司,也在MLOps领域创业。
尽管中国的基础大模型数量可能略逊于海外,但是只要做AI应用,就需要对模型进行微调,也可能会训练垂直行业的甲方大模型,那么对于MLOps就有需求。随着未来越来越多AI应用公司的出现,MLOps有足够大的空间。
而且,MLOps不应该是大厂的机会,而是属于创业公司。因为AI应用公司要与大厂竞争,本身就需要差异化竞争,如果模型的训练和微调都在大厂的平台上进行,那创业公司如何安心?这就和向量数据库还是创业公司做得好是一个逻辑。
基于AI应用即将到来的爆发,以及他们对于MLOps需求的强烈性和普适性,我们预计在中国市场也会有对AI模型训练有深刻理解的创业者在这个方向上创业,这十分令人期待。
文章来自 “钛媒体”,作者 阿尔法公社
网址:Weights&Biases,支持AI明星公司训练模型的幕后英雄 https://mxgxt.com/news/view/183167
相关内容
一家老牌明星AI公司,倒在大模型时代第一批AI明星公司,开始被大厂收购
Meta推出新版自研AI芯片:性能较上代提高三倍,降低对英伟达依赖
大模型拿单江湖
年终盘点:AI大模型今年有哪些变化?
黄山公司健身房器材训练营 室内健身器材 室内运动训练器材
郭德纲讲英文段子?生成式AI做的明星视频翻译或涉侵权
长期坚持平板支撑有什么好处?如何安排平板支撑训练?
英雄联盟全明星赛
明星AI微博,情感伴聊!
随便看看
最新实时动态
- 唐桂林为了上战场报仇冒充男人当兵
- 罗云熙演润玉,香蜜三观跟着五官跑
- 全网最费兄弟的歌出现了
- 被关押的地下党只是看了一眼饭菜,就知道组织有重要事情要联系他
- 易烊千玺 微博VC计划微博VC计划
- 赵露思这程度是完全卸妆成纯素颜了吧
- 真实的路人见到杨超越就这样激动哈哈哈哈哈
- 想到让超哥主持的,真是个天才
- 华妃沦为答应,遥望选秀宫女叹物是人非
- 丈夫谎称冰箱坏了,还发誓一年填满,转头就被牛奶打脸
热点实时动态
- 127597
- 25458
- 20056
- 19741
- 19494
- 19451
- 19186
- 18756
- 18730
- 18706

