基于QLearning强化学习的较大规模栅格地图机器人路径规划matlab仿真
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《 阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写 侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介: 本项目基于MATLAB 2022a,通过强化学习算法实现机器人在栅格地图中的路径规划。仿真结果显示了机器人从初始位置到目标位置的行驶动作序列(如“下下下下右右...”),并生成了详细的路径图。智能体通过Q-Learning算法与环境交互,根据奖励信号优化行为策略,最终学会最优路径。核心程序实现了效用值排序、状态转换及动作选择,并输出机器人行驶的动作序列和路径可视化图。
1.算法仿真效果
matlab2022a仿真结果如下(完整代码运行后无水印):
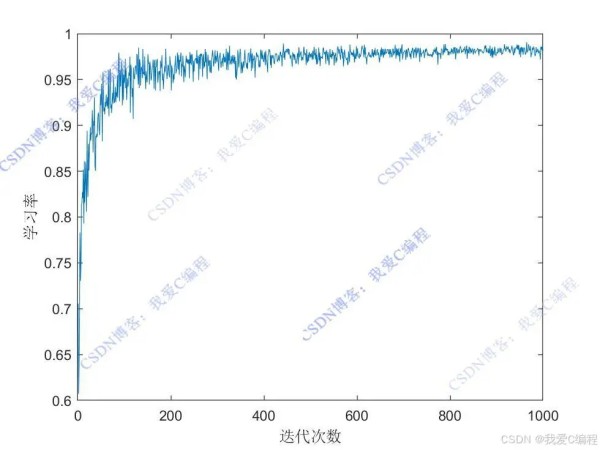
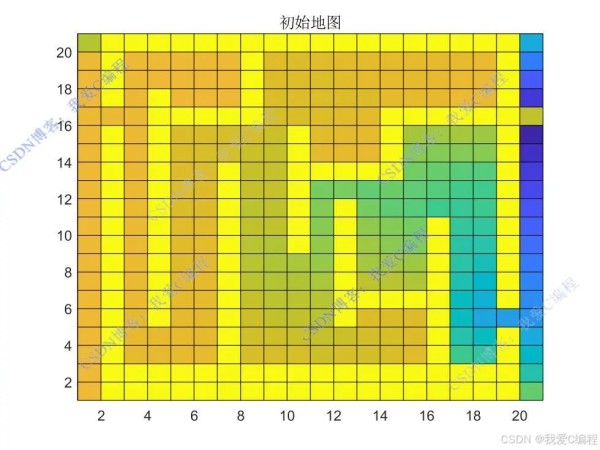
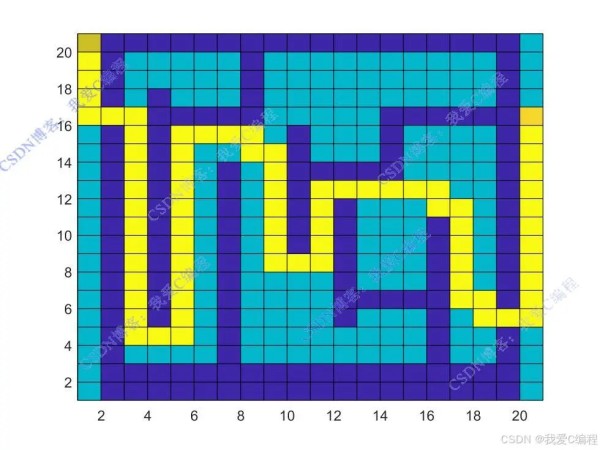
机器人行驶动作序列:
Action_seqs =
'下下下下右右下下下下下下下下下下下下右右上上上上上上上上上上上右右右下右下下下下下下右右上上上上右右右右右下右下下下下下右下右右上上上上上上上上上上上'
仿真操作步骤可参考程序配套的操作视频。
2.算法涉及理论知识概要
强化学习是机器学习中的一个领域,强调智能体(agent)如何在环境(environment)中采取一系列行动(action),以最大化累积奖励(reward)。智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优的行为策略。在机器人导航中,状态可以是机器人的位置和姿态,动作可以是不同的运动指令(如前进、后退、转弯等),奖励可以根据机器人是否接近目标位置或者避开障碍物来设定。通过 Q - Learning,机器人可以学习到从初始位置到目标位置的最优路径规划策略。在机器人路径规划问题中,机器人即为智能体,其所处的大规模栅格地图及相关物理规则等构成了环境 。智能体通过传感器感知环境的状态,并根据学习到的策略在环境中执行动作,如向上、向下、向左、向右移动等,环境则根据智能体的动作反馈相应的奖励信号和新的状态。

将大规模栅格地图表示为一个二维矩阵,其中每个元素对应一个栅格。矩阵中的值可以表示不同的含义,如 表示可通行的栅格, 表示障碍物, 表示目标位置等。同时,定义机器人在栅格地图中的初始位置和目标位置。

经过多次训练后,Q 表逐渐收敛,此时可以根据 Q 表中的值为机器人规划从初始位置到目标位置的最优路径。从初始状态开始,每次选择 Q 值最大的动作,直到到达目标位置,所经过的栅格序列即为规划的最优路径。
3.MATLAB核心程序```% 将效用值和状态的配对按照效用值从小到大的顺序进行排序
Idx_state = [1:nstates]';
% 使用sortrows函数对由效用值U和状态索引estados组成的矩阵按照第一列(即效用值)进行排序
Idxss = sortrows([U Idx_state],1);
Idx_global= [Idx_state,p];
% 获取所有状态在网格上的全局策略
Mat_global= flipdim(reshape(Idx_global(:,2),[Rw1 Cm1]),1);
%输出动作
Action_set = ['上','右','下','左'];
Action_idx = sub2ind(size(Ter1{1}),XY0(1),XY0(2));
Ends = sub2ind(size(Ter1{1}),XY1(1),XY1(2));
Policys = [];% 初始化用于存储策略序列
Action_idx_set = [Action_idx];
while Action_idx~=Ends
if Action_idx~=find(obstacle==1)
% 获取当前状态下的最优策略p
[c1,c2]=ind2sub([Rw1 Cm1],Action_idx);
pop=p(Action_idx);
Action_idx=Ter1{pop}(c1,c2);
% 将本次选择的最优策略添加到策略序列Policys中
Policys = [Policys pop];
Action_idx_set = [Action_idx_set;Action_idx];
end
end
clc;
% 根据策略序列Policys获取对应的动作序列
disp('机器人行驶动作序列:');
Action_seqs = Action_set(Policys)
figure
% 初始化用于存储坐标序列
Posxy = [];
% 创建一个与网格世界维度相同的全零矩阵
Mats1 = zeros(Rw1,Cm1);
% 创建一个与障碍物矩阵obstacle维度相同的矩阵
Mats2 =-75*obstacle;
[Rc11,Cw11] = find(Maps==-1);
J5 = 1;
% 遍历状态序列每个状态索引
for i=1:length(Action_idx_set)
% 根据状态索引Action_idx_set计算其在网格世界中的行坐标c1和列坐标c2
[c1,c2] = ind2sub([Rw1 Cm1],Action_idx_set(i));
% 将当前状态的坐标添加到坐标序列
Posxy = [Posxy;[c1 c2]];
Mats1(end+1-c1,c2)= J5;
Mats2(c1,c2) = 90;
J5=J5+1;
end
Mats2(XY0(1),XY0(2))=50;
Mats2(XY1(1),XY1(2))=75;
Mats2(Rc11,Cw11) =65;
Map_line=[[flipdim(Mats2,1) zeros(Rw1,1)];zeros(1,Cm1+1)];
pcolor(Map_line)
% title(['机器人行驶路线:',Action_seqs]);
0Z_011m
```
网址:基于QLearning强化学习的较大规模栅格地图机器人路径规划matlab仿真 https://mxgxt.com/news/view/1629481
相关内容
【路径规划】基于A求职规划路径图
职业路径规划图工具
SLAM+运动规划=机器人自主定位导航
音乐转型演员的路径怎么规划?
网红职业规划与发展路径.pptx
大学生化学专业职业生涯规划书
分布交互仿真中基于Server的层次过滤机制
一种STEDF的可视图环境建模方法
matlab图像为什么格式,窝窝电影院多多影院?
随便看看
最新实时动态
- 鞠婧祎 在某些方面很相似,粉丝:不,你俩颜值就很大区别微博VC计划
- 卢凌风要铲除壁画,无人敢挡,下秒竟被画师拦住
- 父子俩人互相仇视,杜城:这把高端局 猎罪图鉴2来鹅鉴面
- 听到JUMP的柾国 超开心哈哈 260717 BTS世巡 巴黎演唱会Day1
- “互相迁就,双向奔赴才能真正的长久”电影剪辑
- 安陵容坐矮凳绣暖炉,针线寄情意赠甄嬛
- 功夫女足再现周星驰热巴国民号召力
- 程潇:2026F1中国大奖赛,冷酷有型,极速入境
- 都挺好 苏丽三观为人真是没话说 一直不懂她怎么看上苏明成的
- 《当幸福来敲门》衣衫破旧面试,真诚远比外表重要
热点实时动态
- 129744
- 25462
- 20060
- 19749
- 19497
- 19457
- 19188
- 18757
- 18735
- 18708

