超级干货:一文读懂灰色预测模型

灰色预测模型可针对数量非常少(比如仅4个),数据完整性和可靠性较低的数据序列进行有效预测,其利用微分方程来充分挖掘数据的本质,建模所需信息少,精度较高,运算简便,易于检验,也不用考虑分布规律或变化趋势等。
但灰色预测模型一般只适用于短期预测,只适合指数增长的预测,比如人口数量,航班数量,用水量预测,工业产值预测等。
灰色预测模型有很多,其中GM(1,1)模型使用最为广泛。
灰色关联预测分析GM(1,1)通常可分为以下四个步骤:
(1)级比值检验
此步骤目的在于数据序列是否有着适合的规律性,是否可得到满意的模型等,该步骤仅为初步检验,意义相对较小。
(2)后验差比检验
在进行模型构建后,会得到后验差比C值,该值为残差方差 / 数据方差;其用于衡量模型的拟合精度情况,C值越小越好,一般小于0.65即可。
(3)模型拟合和预测
进行模型构建后得到模型拟合值,以及最近12期的预测值。
(4)模型残差检验
模型残差检验为事后检验法。主要查看相对误差值和级比偏差值。相对误差值=预测拟合值与残差值的差值绝对值 / 原始值。相对误差值越小越好,一般情况下小于20%即说明拟合良好。级比偏差值也用于衡量拟合情况和实际情况的偏差,一般该值小于0.2即可。
一、研究背景
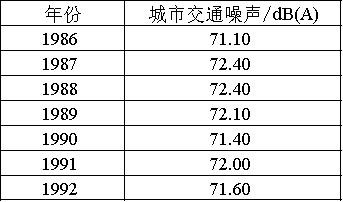
取某地1986年~1992共7年的道路交通噪声平均声级数据进行预测。
二、操作步骤
选择【综合评价】--【灰色预测模型】。
将指标项放入分析框中,点击开始分析。

灰色模型预测
三、结果解读
(1)GM(1,1)模型级比值表格

首先,计算级比值,级比值介于区间[0.982,1.0098]时说明数据适合模型构建。
从上表可知,针对城市交通噪声/dB(A)进行GM(1,1)模型构建,结果显示:级比值的最大值为1.010,在适用范围区间[0.982,1.0098]之外,意味着本数据进行GM(1,1)可能得不到满意的模型。但从数据来看,1.01非常接近于1.0098,因此有理由接着进行建模。
(2)后验差比检验
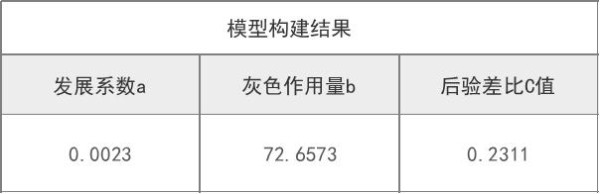
后验差比C值用于模型精度等级检验,该值越小越好,一般C值小于0.35则模型精度等级好,C值小于0.5说明模型精度合格,C值小于0.65说明模型精度基本合格,如果C值大于0.65,则说明模型精度等级不合格。
从上表可知,后验差比C值0.231 <=0.35,意味着模型精度等级非常好。
(3)模型拟合和预测
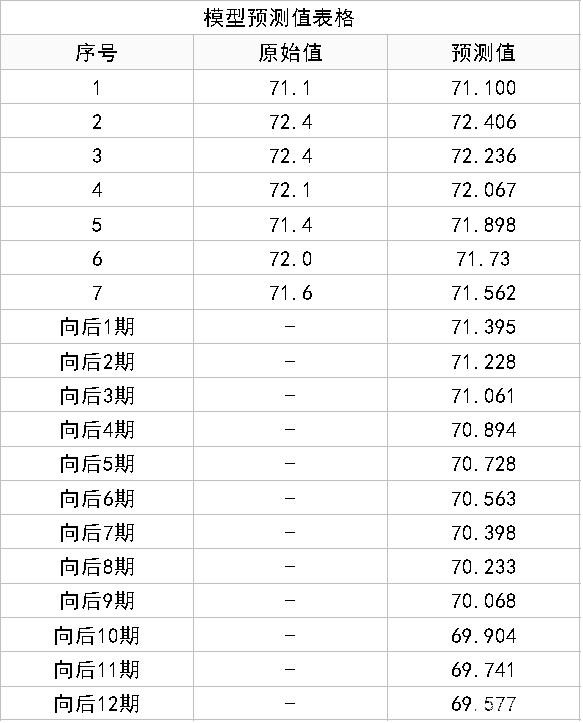
上表格展示出模型的拟合值,以及向后12期的拟合数据情况。
也可通过图形直观查看,下图明显可以看出,往后时会一直下降,这是GM(1,1)模型的特征,其仅适用于中短期预测,因此向后1期和向后2期的数据具有价值,更多的预测数据需要特别谨慎对待。

(4)模型残差检验
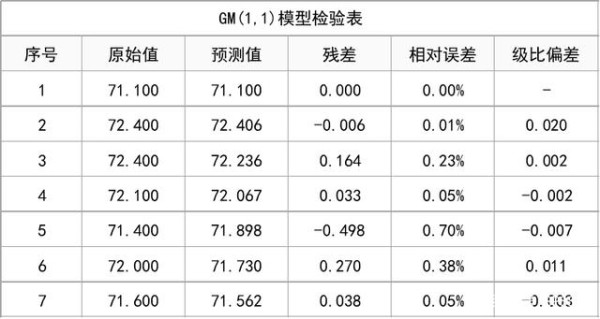
模型残差检验,主要是查看相对误差值和级比偏差值,验证模型效果情况。
从上表可知,模型构建后可对相对误差和级比偏差值进行分析,验证模型效果情况;模型相对误差值最大值0.007<0.1,意味着模型拟合效果达到较高要求。
针对级比偏差值,该值小于0.2说明达到要求,若小于0.1则说明达到较高要求;模型相对误差值最大值0.020<0.1,意味着模型拟合效果达到较高要求。
四、其他说明
灰色预测的主要特点是模型使用的不是原始数据序列,而是生成的数据序列。适用于少量数据时使用(比如20个以内),大量数据时不适合。
GM(1,1)模型仅适用于中短期预测,不建议进行长期预测。
GM(1,1)模型有提供级比值检验,后验差比检验,模型残差检验等;并非所有检验均能完美,通常在可容忍范围内即可。
网址:超级干货:一文读懂灰色预测模型 https://mxgxt.com/news/view/137456
相关内容
周鸿祎预测诺贝尔奖项:ChatGPT或得诺贝尔文学奖风暴潮预警颜色等级划分有哪些?一文读懂
感受一下超模张丽娜这气场总能把look穿得高级得“深不可测”
秋天跟着超模学穿搭,简单基础款也可以轻松演绎时髦高级感
奚梦瑶 下一个中国超模
深度解析:目标检测领域的明星模型Faster R
优衣库:“超级明星店长制”
美国十大美女模特 著名美国超模盘点 美国名模有哪些
一文读懂日本30年时尚变迁史
苏珊·米勒预测:超级明星情侣喜结良缘,2024年将举行婚礼
随便看看
最新实时动态
- 陈伟霆和章若楠这两个高颜值二搭真的好养眼啊,俩人大大方方互动真的有点好磕
- 郑晓龙称拍甄嬛传为批判,千红一窟万艳同悲
- 这一秒过火定档719!
- 小向离家出走生活不易,家里人断舍离式捐物资
- 雀骨:既然不爱她 还要把她绑在身边 这个渣爹太坏了
- 百花杀:太子信王正面交锋
- 260711|他人vlog 合集刘宇CUT
- 沈雁回计划暴露被抓,定王代替她喝下毒酒 !
- 古代有个当皇帝的兄弟有多爽 皇上命我选妃
- 书卷一梦:这俩人每人这下得有八百个心眼子
热点实时动态
- 129171
- 25461
- 20059
- 19748
- 19496
- 19454
- 19187
- 18756
- 18734
- 18706

