半个小时看懂用户画像(下)【如何构建用户画像】
是新朋友吗?记得先点蓝字关注我哦~
用户画像的上一篇文章,和大家聊了一下用户画像的基本概念、应用场景和数据来源,今天这篇文章会重点给大家讲讲如何构建用户画像,这是大家所比较关心的。构建用户画像的步骤,我总结如下:
第一步,ID-Mapping
第二步,构建标签体系
第三步,构建用户画像
第四步,用户画像评估
ID-Mapping
ID-Mapping是大数据分析中非常基本但又特别关键的环节,把几份不同来源的数据,通过各种技术手段识别为同一个对象,比如同一台设备,同一个用户,同一个企业等等。可以形象地理解为用户画像的“拼图”过程。
一个用户的行为信息、属性数据是分散在很多不同的数据来源的,因此从单个数据来看,看到的只是这个用户的片面画像,而ID-Mapping能把碎片化的数据全部串联起来,消除数据孤岛,提供一个用户的完整信息视图。
ID-Mapping有非常多的用处,比如跨屏跟踪和跨设备跟踪,将一个用户的手机、PC、平板等设备上的行为信息串联在一起。PC时代,打通用户行为数据的重任是在Cookie上,匹配率不是特别理想。移动互联网时代,则落在手机设备ID上,设备ID相对易获取,且稳定,匹配率高。整个手机行业,Android和苹果等两个操作系统是主流,但由于Android和苹果的系统开放程度不同,所能获取到的设备ID权限也不同,苹果比起Android要严格得多。
构建标签体系
什么是标签体系?要理解标签体系,首先来理解一下什么是标签?标签是对某一类特定群体或对象的某项特征进行的抽象分类和概括,其值(标签值)具备可分类性。比如“大学生”这个标签,其实就是对所有大学生群体的总括,细分这一标签,还可以分为年级、专业等,通过不同层级的标签找到某一群用户。
那么什么是标签体系?就是你要把用户分到多少个类标签里面去,每个用户既可以分到多个类,也可以分到一个类上。这些类标签相互联系,共同组成了标签体系。比如“基本属性”、“行为特征”、“社交网络”、“心理特征”、“兴趣偏好”等。
目前主流的标签体系都是层次化的,如下图。首先标签分为几个大类,每个大类下进行逐层细分。在构建标签时,只需要构建最下层的标签,就能够映射到上面两级标签。上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签本身对广告投放没有任何意义。
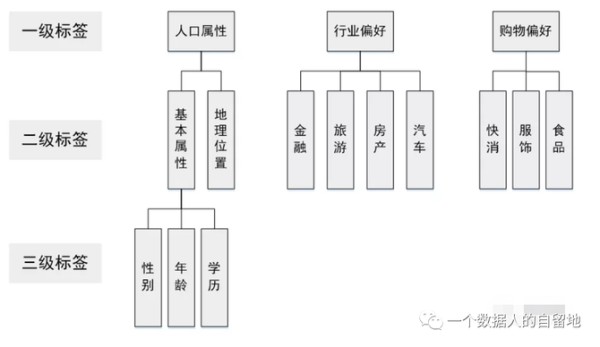
最后说说各类标签构建的优先级。构建的优先级需要综合考虑业务需求、构建难易程度等,业务需求各有不同,这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系。
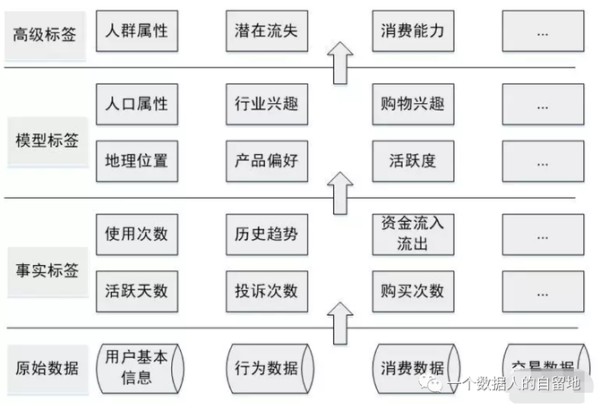
构建用户画像
通常我们把用户画像分为三类,这三类有较大的差异,构建时用到的技术差别也很大。
人口属性,这一类画像比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定;
兴趣属性,这类画像随时间变化很快,画像有很强的时效性,标签体系也不固定;
地理属性,这一类画像的时效性跨度很大,如GPS轨迹画像需要做到实时更新,而常住地属性一般可以几个月不用更新,挖掘的方法和前面两类也大有不同。
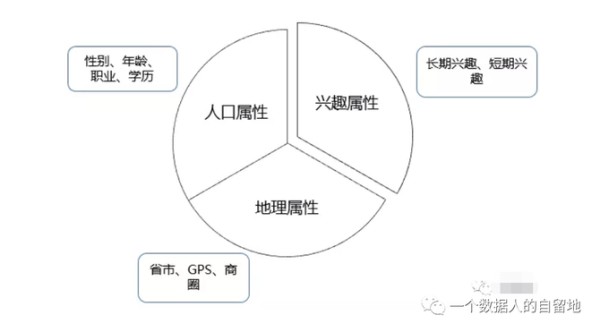
人口属性画像
人口属性包括年龄、性别、学历、人生阶段、收入水平、消费水平、所属行业等。这些属性基本是稳定的,构建一次可以很长一段时间不用更新,画像的有效期都在一个月以上。
很多产品(如QQ、淘宝、支付宝等)都会引导用户填写基本信息,这些信息就包括年龄、性别、收入等大多数的人口属性,但完整填写个人信息的用户只占很少一部分。而对于无社交属性的产品(如输入法、团购APP、视频网站等)用户信息的填充率非常低,有的甚至不足5%。
在这种情况下,一般会用填写了信息的这部分用户作为样本,把用户的行为数据作为特征训练模型,对无属性的用户进行人口属性的预测。这种模型把用户的标签传给和他行为相似的用户,可以认为是对人群进行了标签扩散,因此常被称为人群扩散模型(Lookalike模型)。
经验表明,对于预测性别这样的二分类模型,如果行为的区分度较好,一般准确率和覆盖率都可以达到70%左右。
对于其他人口属性标签,只要有一定的样本标签数据,并找到能够区分标签分类的用户行为特征,就可以构建人群扩散模型。其中使用的技术方法主要是机器学习中的分类技术,常用的模型有LR、FM、SVM、GBDT等。
兴趣画像
兴趣画像是互联网领域使用最广泛的画像,互联网广告、个性化推荐、精准营销等各个领域最核心的标签都是兴趣标签。兴趣画像主要是从用户海量行为日志中进行核心信息的抽取、标签化和统计,因此在构建用户兴趣画像之前需要先对用户有行为的内容进行内容建模。
内容建模需要注意粒度,过细的粒度会导致标签没有泛化能力和使用价值,过粗的粒度会导致没有区分度。
为了保证兴趣画像既有一定的准确度又有较好的泛化性,通常会构建层次化的兴趣标签体系,使用中同时用几个粒度的标签去匹配,既保证了标签的准确性,又保证了标签的泛化性。下面用新闻的用户兴趣画像举例,介绍如何构建层次化的兴趣标签。
比如,内容建模,拿新闻数据来说,它是一种非结构化得数据源,首先需要人工构建一个层次的标签体系。

首先,这是一篇体育新闻,体育这个新闻分类可以表示用户兴趣,但是这个标签太粗了,用户可能只对篮球感兴趣,体育这个标签就显得不够准确。
其次,可以使用新闻中的关键词,尤其是里面的专有名词(人名、机构名),如“哈登”、“保罗”、“火箭”,这些词也表示了用户的兴趣。关键词的主要问题在于粒度太细,如果一天的新闻里没有这些关键词出现,就无法给用户推荐内容。
最后,希望有一个中间粒度的标签,既有一定的准确度,又有一定的泛化能力。于是我们尝试对关键词进行聚类,把一类关键词当成一个标签,或者把一个分类下的新闻进行拆分,生成像“篮球”这种粒度介于关键词和分类之间的主题标签。最后可以使用文本主题聚类完成主题标签的构建。
因此就完成了对新闻内容从粗到细的“分类-主题-关键词”三层标签体系内容建模,新闻的三层标签。
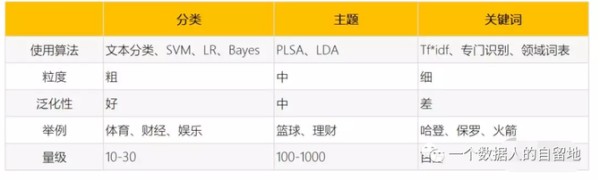
既然主题的准确率和覆盖率都不错,只使用主题不就可以了嘛?为什么还要构建分类和关键词这两层标签呢?这么做是为了给用户进行尽可能精确和全面的内容推荐。
当用户的关键词命中新闻时,显然能够给用户更准确的推荐,这时就不需要再使用主题标签;而对于比较小众的主题(如体育类的冰上运动主题),若当天没有新闻覆盖,就可以根据分类标签进行推荐。层次标签兼顾了对用户兴趣刻画的覆盖率和准确性。
地理位置画像
地理位置画像一般分为两部分:一部分是常驻地画像;一部分是GPS画像。两类画像的差别很大,常驻地画像比较容易构造,且标签比较稳定,GPS画像需要实时更新。
常驻地包括国家、省份、城市三级,一般只细化到城市粒度。常驻地的挖掘基于用户的IP地址信息,对用户的IP地址进行解析,对应到相应的城市,对用户IP出现的城市进行统计就可以得到常驻城市标签。
用户的常驻城市标签,不仅可以用来统计各个地域的用户分布,还可以根据用户在各个城市之间的出行轨迹识别出差人群、旅游人群等,如下图所示是人群出行轨迹的一个示例。
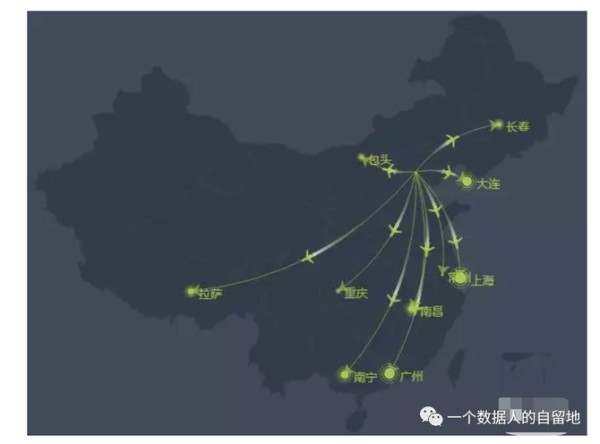
GPS数据一般从手机端收集,但很多手机APP没有获取用户GPS信息的权限。能够获取用户GPS信息的主要是百度地图、滴滴打车等出行导航类APP,此外收集到的用户GPS数据比较稀疏。
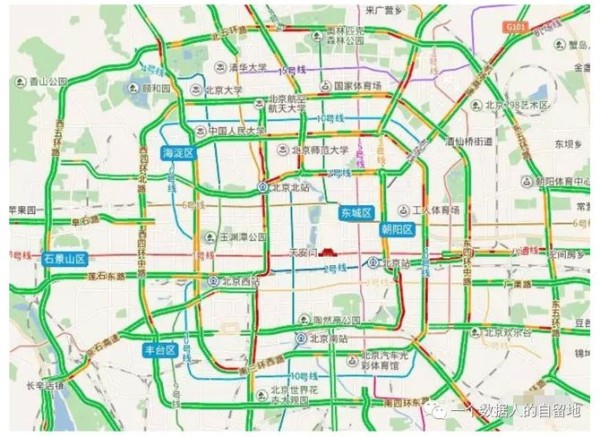
百度地图使用该方法结合时间段数据,构建了用户公司和家的GPS标签。此外百度地图还基于GPS信息,统计各条路上的车流量,进行路况分析,如下图是北京市的实时路况图,红色表示拥堵线路。
用户画像评估
人口属性画像的相关指标比较容易评估,而兴趣画像的标签比较模糊,兴趣画像的人为评估比较困难,对于兴趣画像的常用评估方法是设计小样本的A/B-test进行验证。
可以筛选一部分目标检测标签用户,给这部分用户进行和标签相关的推送,看标签用户对相关内容是否有更好的反馈。
例如,在新闻推荐中,给用户构建了兴趣画像,从体育类兴趣用户中选取一小批用户,给他们推送体育类新闻,如果这批用户的点击率和阅读时长明显高于平均水平,就说明标签是有效的。
用户画像效果最直接的评估方法就是看其对实际业务的提升,如互联网广告投放中画像效果主要看使用画像以后点击率和收入的提升,精准营销过程中主要看使用画像后销量的提升等。
但是如果把一个没有经过效果评估的模型直接用到线上,风险是很大的,因此需要一些上线前可计算的指标来衡量用户画像的质量。
用户画像的评估指标主要是指准确率、覆盖率、时效性等指标。
准确率
标签的准确率指的是被打上正确标签的用户比例,准确率是用户画像最核心的指标,一个准确率非常低的标签是没有应用价值的。
准确率的评估一般有两种方法:一种是在标注数据集里留一部分测试数据用于计算模型的准确率;另一种是在全量用户中抽一批用户,进行人工标注,评估准确率。
由于初始的标注数据集的分布和全量用户分布相比可能有一定偏差,故后一种方法的数据更可信。准确率一般是对每个标签分别评估,多个标签放在一起评估准确率是没有意义的。
覆盖率
标签的覆盖率指的是被打上标签的用户占全量用户的比例,我们希望标签的覆盖率尽可能的高。但覆盖率和准确率是一对矛盾的指标,需要对二者进行权衡,一般的做法是在准确率符合一定标准的情况下,尽可能的提升覆盖率。
我们都希望覆盖尽可能多的用户,同时给每个用户打上尽可能多的标签,因此标签整体的覆盖率一般拆解为两个指标来评估。一个是标签覆盖的用户比例,另一个是覆盖用户的人均标签数,前一个指标是覆盖的广度,后一个指标表示覆盖的密度。
时效性
有些标签的时效性很强,如兴趣标签、出现轨迹标签等,一周之前的就没有意义了;有些标签基本没有时效性,如性别、年龄等,可以有一年到几年的有效期。对于不同的标签,需要建立合理的更新机制,以保证标签时间上的有效性。
其他指标
标签还需要有一定的可解释性,便于理解;同时需要便于维护且有一定的可扩展性,方便后续标签的添加。这些指标难以给出量化的标准,但在构架用户画像时也需要注意。
一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘
网址:半个小时看懂用户画像(下)【如何构建用户画像】 https://mxgxt.com/news/view/136994
相关内容
你确定你真的懂用户画像?小红书要多少粉丝才能看用户画像
最佳综艺用户画像
东君:我写小说,像是用文字来画画
东君谈《无雨烧茶》:我写小说,像是用文字来画画
画名人肖像是否涉及侵权
爱豆传媒网站最新进展:全新功能上线,用户体验大幅提升,助力粉丝与偶像互动更紧密
偶像选秀三年之殇:难现“杨超越” 用户已疲劳
画牛大师画9头牛,卖2100万,他画牛不用笔,一头牛照样卖1.6亿
5亿微博用户数据泄露,查到明星网红手机号,如何保护个人信息?
随便看看
最新实时动态
- 训斥余莺儿后,皇帝破格晋封甄嬛为莞贵人
- 这俩人演傻子绝对是本色出演,一对卧龙凤雏!哈哈哈
- 以问答为赌注 陆千乔棋局交锋
- 师姐妹落难在牢里重逢
- 单依纯走红毯没憋住笑哈哈!红毯 微博VC计划
- 李菲儿:做过什么疯狂的事吗? 金莎直言带男友上恋综,这是能说的吗?
- 最能隐忍的大胖遇上最能怼人的金豆豆
- 一看就知道是谁想拍的
- 星爷新片《功夫女足》,热巴张小斐素颜反差感拉满
- 改头换面说《延河》
热点实时动态
- 136593
- 25503
- 20096
- 19787
- 19531
- 19489
- 19225
- 18793
- 18772
- 18745

