机器学习——海量数据挖掘解决方案
发布时间:2025-05-08 04:51
图 5 SVM核函数的作用原理图
SVM如何规避过拟合
过拟合(Overfitting)表现为在训练数据上模型的预测错误很低,在未知数据上预测错误却很高。图6的蓝色曲线代表训练错误,红色曲线代表真实错误,可以看到随着模型复杂度的升高,模型对训练数据的拟合程度越好(训练错误越低),但到了一定程度之后真实错误反而上升,即为过拟合。
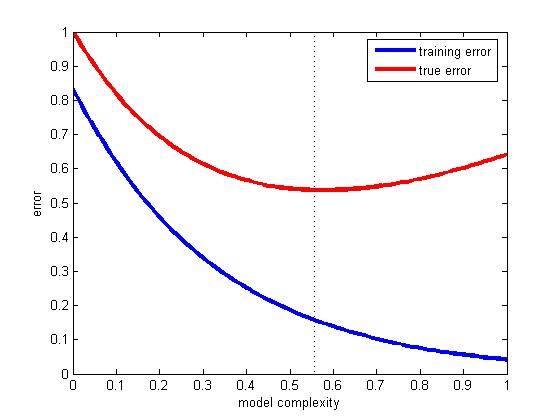
图 6 过拟合
过拟合主要源于我们采集的训练样本带有噪声,有部分样本严重偏离其正常位置,统计学上称之为outlier。前面已经提到,决定SVM最优分类面的只是占少数的支持向量,如果碰巧这些支持向量中存在outlier,而我们又要求SVM尽可能完美的去拟合这样的数据,得到的分类面可能就会有问题。如图7所示,黑色加粗虚线代表最优分类面,带黑圈的蓝色数据点代表outlier。可以看到outlier严重偏离了正常蓝色数据点的位置,所在位置又恰巧使其成为了支持向量,导致了最终的分类面(深红色实线)严重偏离最优分类面。
6/11 首页 上一页 4 5 6 7 8 9 下一页 尾页
网址:机器学习——海量数据挖掘解决方案 https://mxgxt.com/news/view/1049703
相关内容
大数据挖掘算法实战:如何挖掘海量数据中的隐藏价值如何给网红做数据挖掘方案
一文弄懂数据挖掘的十大算法,数据挖掘算法原理讲解
网络舆情数据挖掘方案
数据挖掘方法与股价预测
数据挖掘是对业务和用户的理解
娱乐行业数据挖掘与应用
基于机器学习的相关新闻事件挖掘
网络社交媒体数据挖掘与情感分析
数据挖掘过程中数据质量常见处理方法 大数据行业资讯
随便看看
最新实时动态
- 没有B柱,太方便啦!
- 网传《狐妖小红娘竹业篇》暂定陈晓刘诗诗,杨洋再拒大热IP仙侠剧 陈晓 杨洋
- 王祖蓝已立遗嘱,上亿财产全给老婆
- 1997年刘德华点评周星驰人品,莫文蔚吓得当场变脸
- 221106三角函数公演《就差一点点》宋昕冉直拍 尼克狐尼克冉星河入夢1637
- 父女的重逢场面,一句台词都没有却看哭无数人的心
- 时隔四年再回味沉香,剧情、服化道全在线,经典仙侠永不褪色,四周年喜乐!
- 为爱放弃比赛冲入暴雨,愧疚关系走向万劫不复
- 亲兄弟命运颠倒,真少爷被锁地牢,假少爷霸占妻儿家产
- 假仙最懂人间事:品读《红楼梦》张道士
热点实时动态
- 134604
- 25478
- 20076
- 19762
- 19508
- 19467
- 19199
- 18771
- 18748
- 18722

